In this section, the different deployment possibilities are described.
Thanks to Nuxeo Runtime and to the bundle system, the Nuxeo Platform deployment can be adapted to your needs:
- Deploy only the bundles you really need
- Deploy on multiple servers if needed
- Deploy on multiple infrastructures: Tomcat, Pojo, unit tests
Simple Deployment
For a simple deployment you have to:
- Define the target Nuxeo distribution (in most of the cases Nuxeo CAP + some extra plugins)
- Define the target deployment platform:
- Prepackaged Tomcat Server (including Nuxeo + Transaction manager + JCA + Pooling)
- Static WAR (see Understanding Bundles Deployment)
- Embedded mode (mainly for unit tests, but also used for some client side deployment)
The default Tomcat packaging is actually not a bare Tomcat. The Tomcat that is shipped with Nuxeo contains:
- A JTA Transaction Manager
- A JCA pool manager
In most of the case, the Nuxeo server is behind a reverse proxy that is used to provide:
- HTTPS/SSL encryption
- HTTP caching
- URL rewritting
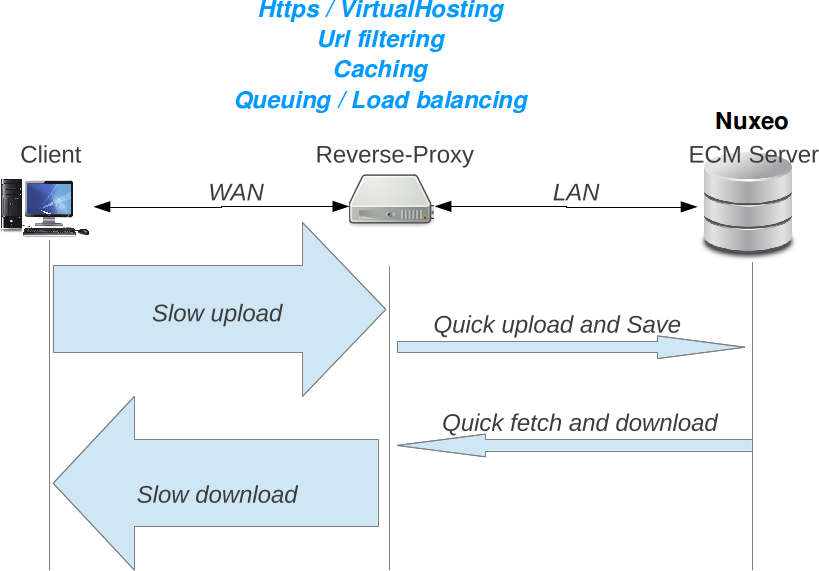
Additionally, when some clients use a WAN to access the server, the reverse proxy can also be used to protect the server against slow connections that may use server side resources during a long time.
Storage Alternatives
Nuxeo Platform is pluggable so that it can be adapted to different deployment environments and use cases.
This means you can define "where you want to manage your data" and because the answer may depend on the type of data, Nuxeo Platform provides different types of backend for different types of storage.
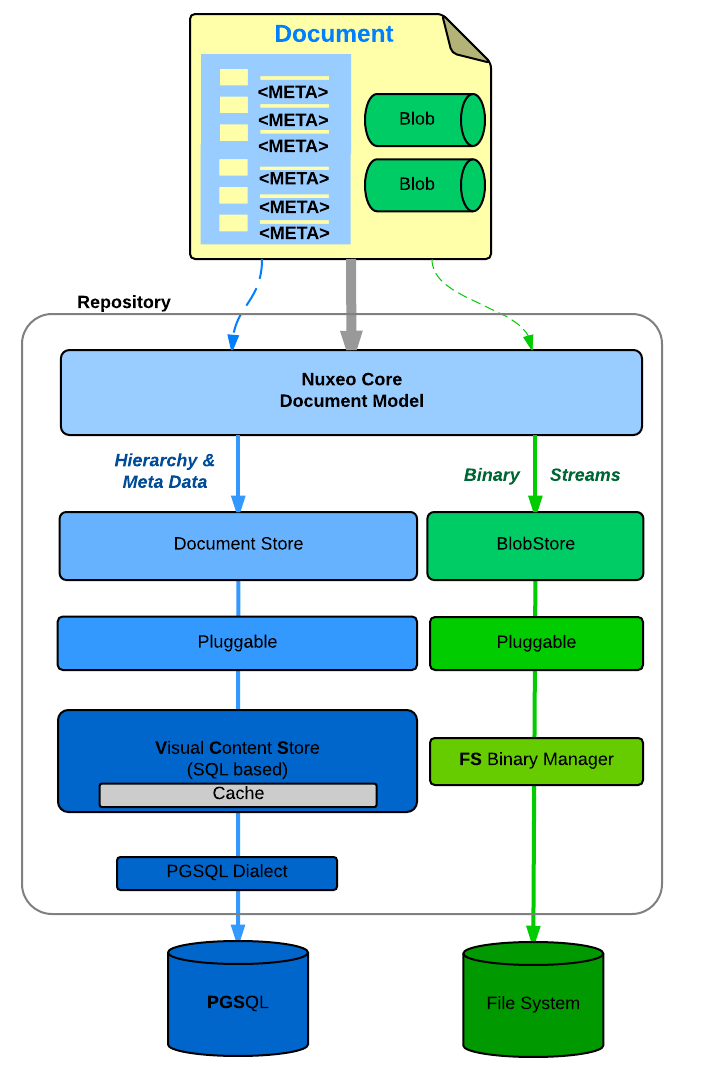
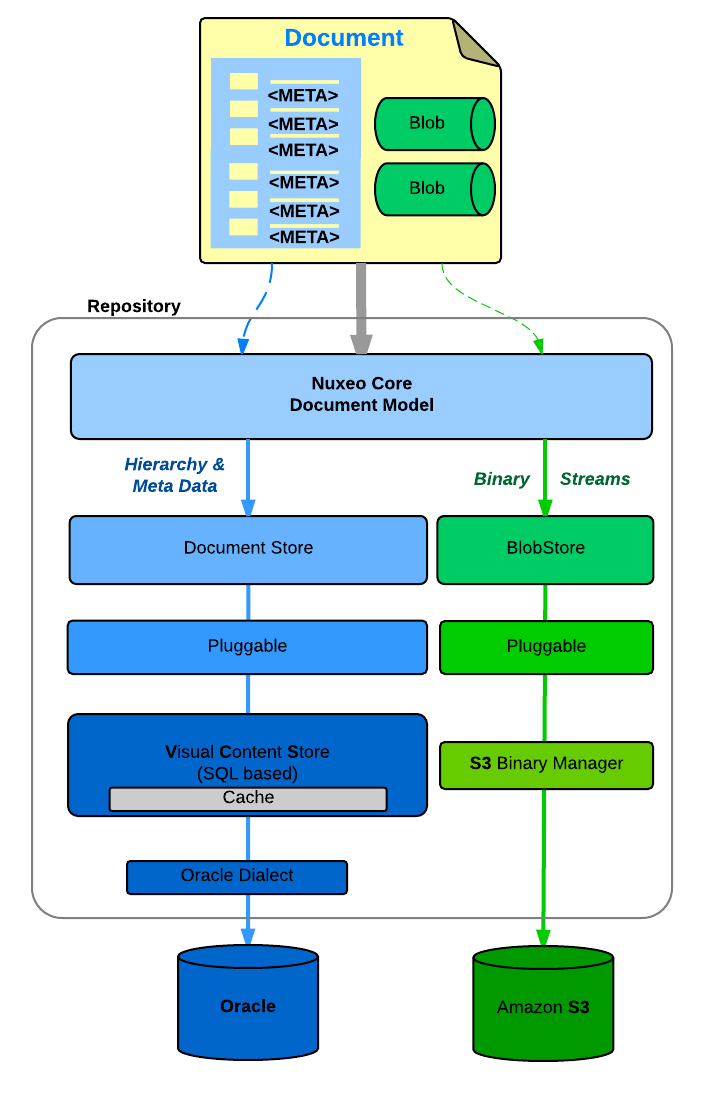
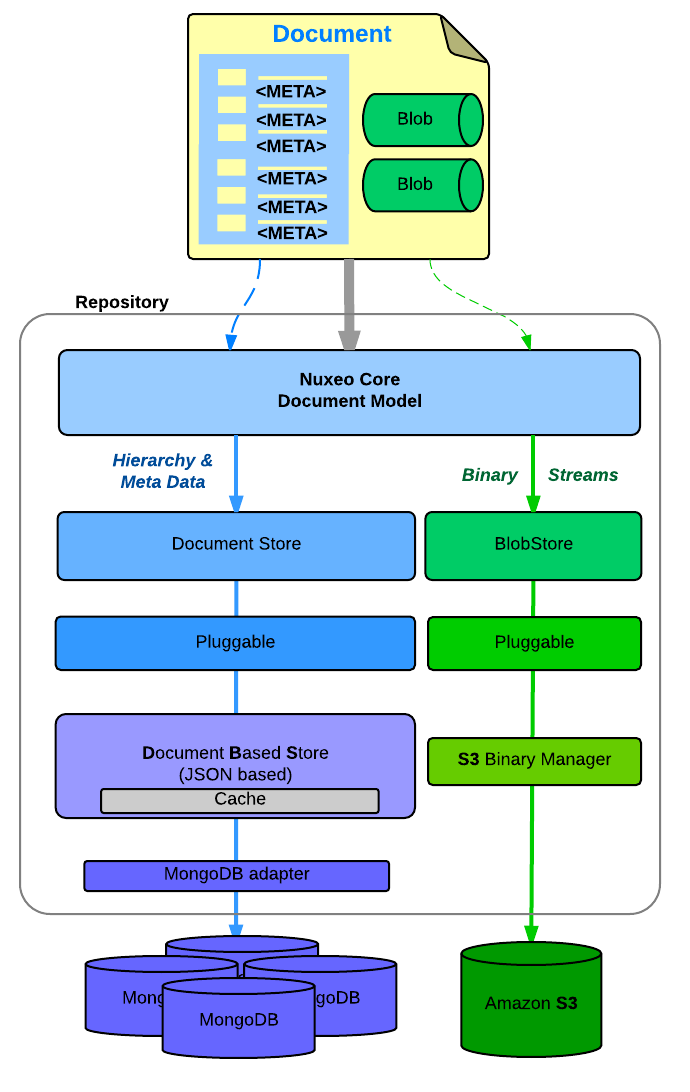
Document Storage
You can configure
- Where you store the Document meta-data and hierarchy
- SQL Database (PostgresSQL, Oracle, MSSQL, MySQL, Amazon RDS)
- MongoDB
- Where you store the binary streams (the files you attach to documents)
- Simple FileSystem
- SQL Database
- S3, Azure
- Leveraging Content Delivery Networks for caching content securely all around the globe.
|
|
|
| PosgreSQL + FileSystem | Oracle + S3 | MongoDB + S3 |
Indexes
You can also select where you store the indexes (including the full-text)
- SQL Database
- Elasticsearch
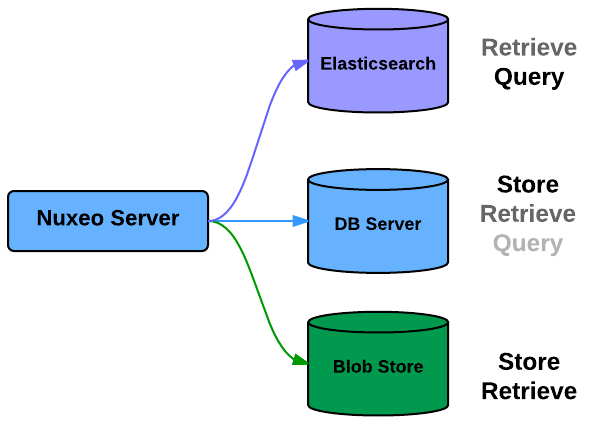
Since 6.0, the default configuration uses Elasticsearch.
Others
In the same logic, you can choose:
Where you store the caches and the transient data
- In Memory (per instance basis)
- Redis (shared memory)
- Where you store Users and Groups
- SQL Database
- LDAP
- Mix of both
- External system
Scalability and High Availability
Cluster HA
In order to manage scale out and HA, the Nuxeo Platform provides a simple clustering solution.
When cluster mode is enabled, you can have several Nuxeo Platform nodes connected to the same database server: you can then simply add more Nuxeo Server if you need to serve more requests.
Nuxeo Repository cluster mode manages the required cache invalidation between the nodes. There is no need to activate any application server level cluster mode: cluster mode works even without application server.
The default caching implementation uses simple JVM Memory, but we also have alternate implementation for specific use cases.
Depending on the UI framework used for presentation layer, the network load balancing may need to be stateful.
Typically:
- JSF Backoffice UI is stateful,
- WebEngine and HTML/JS based UI are mainly stateless.
Anyway, even with JSF:
- Authentication can be transparent if you use a SSO system,
- The Nuxeo Platform knows how to restore a JSF view from a URL (most Nuxeo JSF views are bound to REST URLs).
When running in Cluster mode, the usage of Redis is strongly recommended since it allows to:
- Share caches between the nodes
- Making the caches more efficient
- Avoiding invalidation issues
- Share the Work queues (all the asynchronous jobs that have been scheduled)
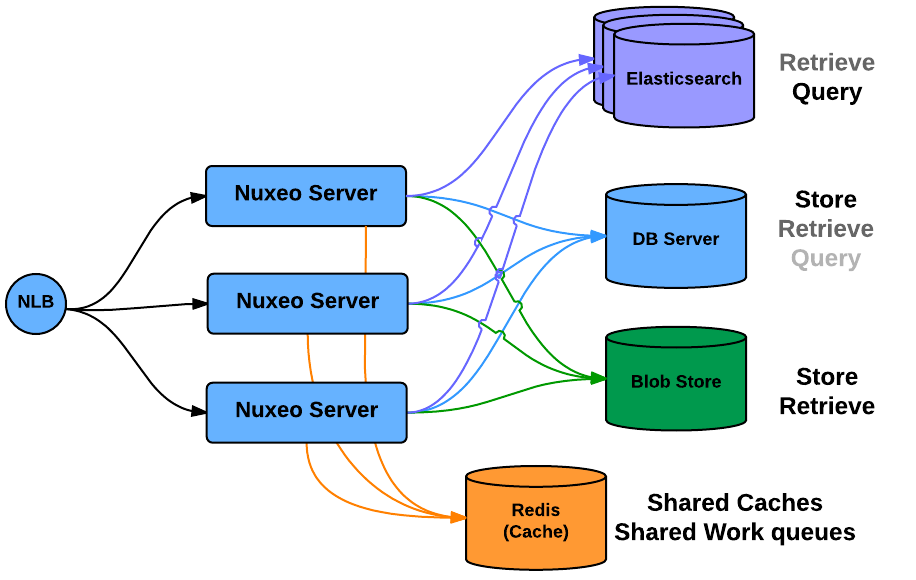
In this architecture the Database server is still a Single Point of Failure.
To correct that, the you have several options:
- Use Nuxeo Clustering + Database replication as described below
- Use Nuxeo Clustering + a Clusterized database (like Oracle RAC)
- Use Nuxeo Clustering + a distributed/failsafe Database like MongoDB
For more information, please see the page Setting up a HA Configuration Using the Nuxeo Platform and PostgreSQL.
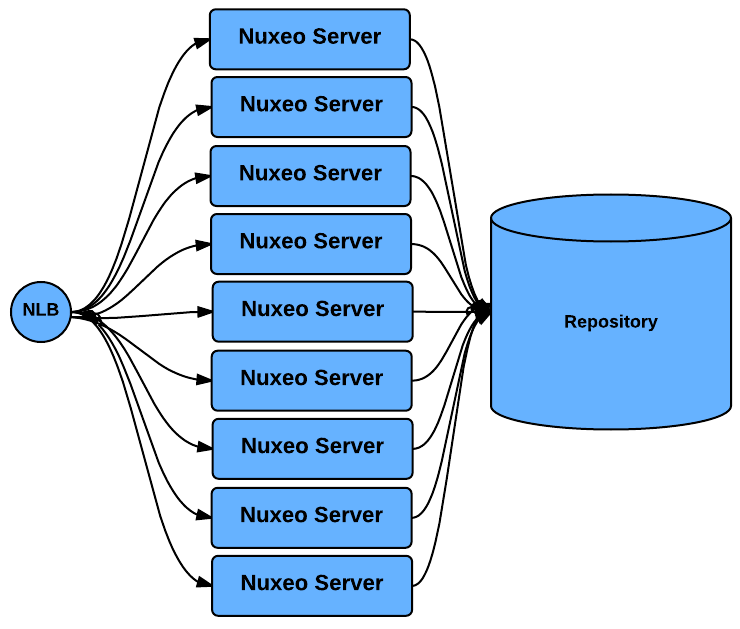
Scaling out Processing
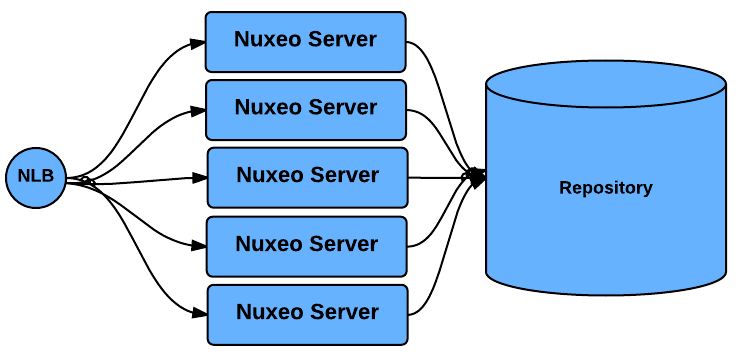
| Nuxeo Cluster system by itself allows to scale out processing: you can add new Nuxeo nodes as the number of requests increase. |
Dedicated Processing Nodes
The async tasks can be managed in a distributed way using the WorkManager and Redis.
This can be used to have some nodes of the Cluster dedicated to some heavy processing like Picture or Video conversions.
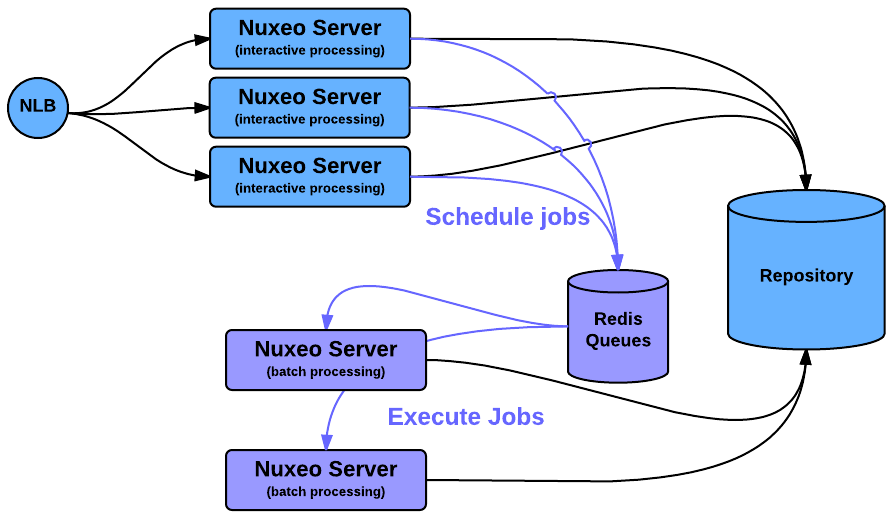
Having such a demarcation between nodes is also a good way to be sure that async processing won't slow down Interactive processing.
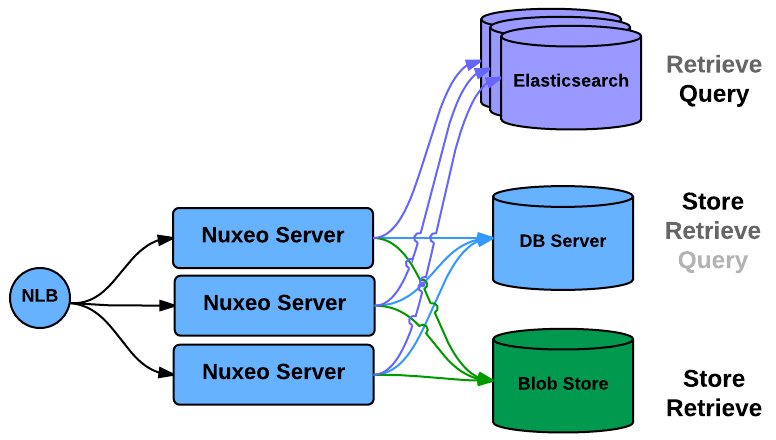
/default/. But you can add new repositories as needed. These new repositories will appear inside the application as several content roots. This typically means that when accessing a document, you have to know what is the host repository.
Typical use cases for data partitioning include:
Selecting your storage type according to the needs
Partitioning between Live and Archive documents:
Archive
Storage: slower but massive cheap storage that can scale
Indexes: add indexes on the database to make search faster (few Write)
Live
Storage: fast storage to make work faster, lower volume
Indexes: fast database with few index to maximize write speed
Partitioning between read-only and read-write repositories
Have a read-write repository
Have a read-only replicated repository
Selecting the storage according to the isolation policy
Data for "clientX" goes in "repositoryX"
Partitioning between types of documents or document status:
Published documents in a public repository
Working documents in a restricted repository
This data partitioning is visible to user, but thanks to Elasticsearch we can provide a unified Index
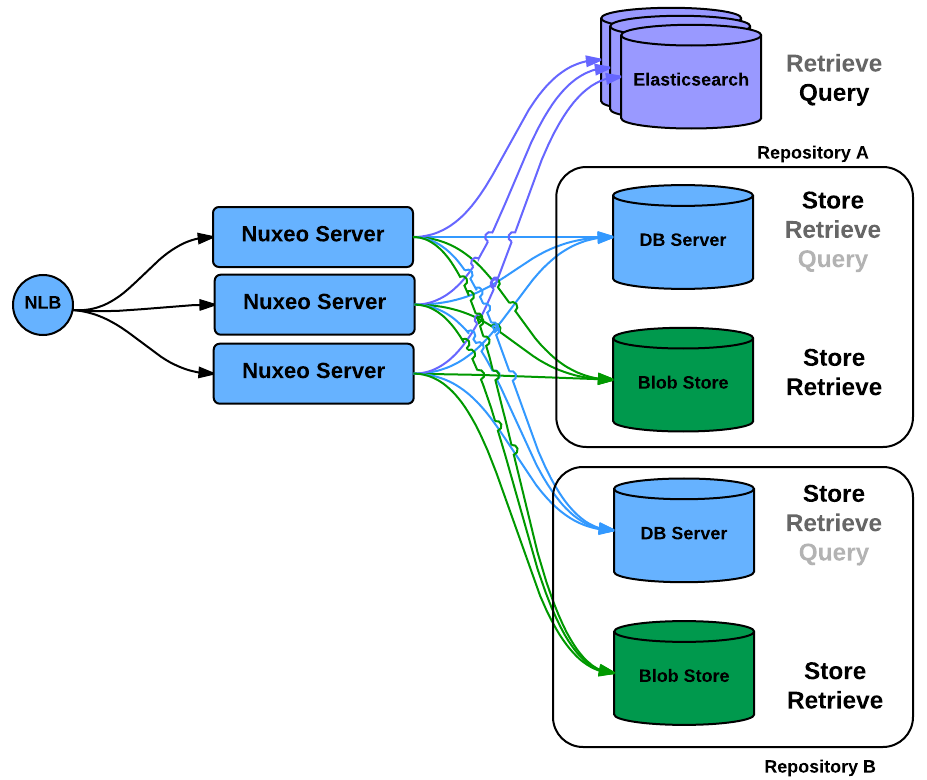
One the key advantages of NoSQL Storage like MongoDB is that they allow to scale out by simply adding nodes to the cluster and propose natively sharding on the nodes.
Cloud & PaaS and Deployment Automation
Nuxeo & AWS
To be able to run efficiently on the Cloud, you need to be able to use as much as possible the infrastructure of the Cloud Provider: in the case of AWS, there are a lot of services that you want to be able to use.
Nuxeo Platform, makes it easy since:
- We are standard based
- The pluggable component model (Extension Point) allows to easily change backend implementation when needed
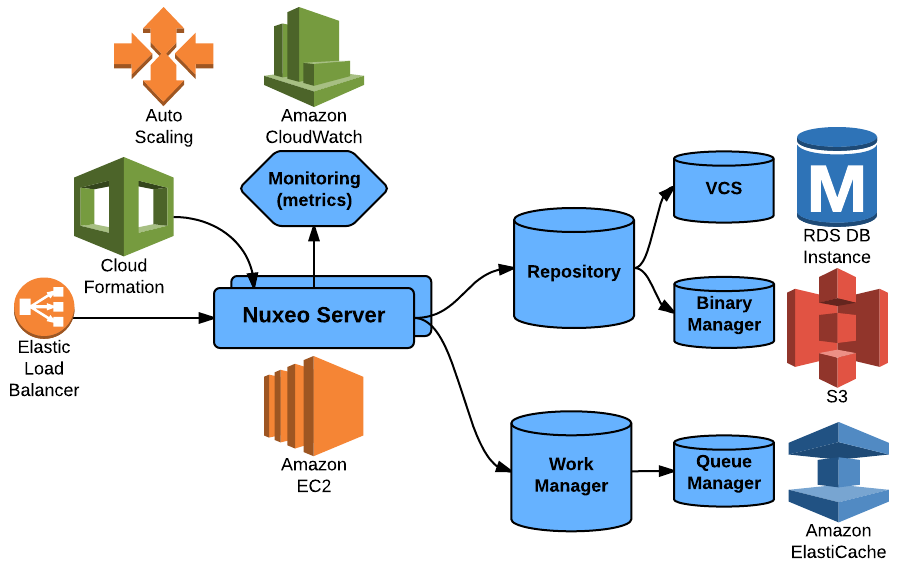
That's why leveraging AWS infrastructure was almost a natural fit for Nuxeo:
- Meta-Data Store: Oracle RDS or PostgreSQL RDS
- Native plug (nothing specific to AWS)
- Binary Store: S3 Binary Store
- Our BinaryManager is pluggable and we use it to leverage the S3 Storage capabilities
- Cache: ElasticCache / Redis
- Our cache infrastructure is pluggable to support Redis
- Our distributed Job queuing was already Redis based
The same idea is true for all the Cloud Specific services like provisioning and monitoring.
We try to provide everything so that the deployment in the target IaaS is easy and painless:
- Nuxeo is packaged as Debian packages (this is one of the available packaging)
- We can easily setup Nuxeo on top of AMI
- We can use CloudFormation
- Nuxeo exposes its metrics via JMX
- CloudWatch can monitor Nuxeo
- We can use AutoScaling
Platform as a Service and nuxeo.io
Cloud infrastructure pricing is a complex task: you just need to take a look at the AWS pricing rules to be convinced of that.
However, there are great optimizations opportunities:
- Reserved instance are significantly cheaper if you can commit in long term
- Sport instances can be a great solution if you can cope with their transient nature
Being able to leverage these opportunities implies to distribute the applications parts across enough VM so that:
- You can use all the resources available
- You can loose VMs without breaking the system
At Nuxeo, we use Docker to multiplex several Nuxeo Applications on top of a set of AWS VMs running CoreOS.
Using this architecture provide high resilience, fast scale out and a very efficient performance / cost ratio.
This was one of the starting point of the nuxeo.io architecture that uses Docker to provide on demande Nuxeo Platform deployment.
Other Deployment Options
Hot Standby (DRP)
If you want to provide a Disaster Recovery Plan, you need to host two separated Nuxeo infrastructures and be sure you can switch from one to an another in case of problem.
The first step is to deploy two Nuxeo infrastructures on two hosting sites. These infrastructure can be mono-VM, cluster or multi-VM. The key point is to provide a way for each hosting site to have the same vision of the data:
- SQL data stored in the SQL database server,
- Filesystem data.
Because Nuxeo storage VCS+Filesystem is safe, you can use a replication system between the two sites. Basically, you can use the replication/standby solution provided by the database server you choose. This replication tool just has to be transactional.
For the filesystem, any replication system like RSync can be used.
Because the blobs are referenced by their digest in the database, you don't have to care about synchronization between the DB and FS: In the worst case, you will have blobs that are not referenced by the DB on the replicated site.
This kind of DRP solution has been successfully tested in production environment using:
- PosgreSQL stand-by solution (WAL shipping),
- RSync for the file system.
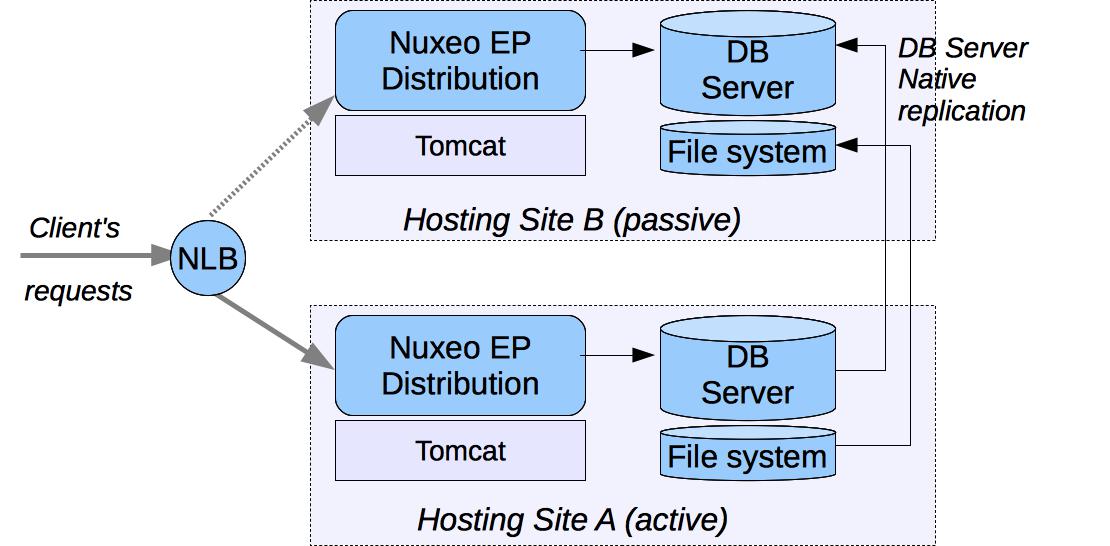
The Warm standby DB nodes are not used by Nuxeo active nodes.
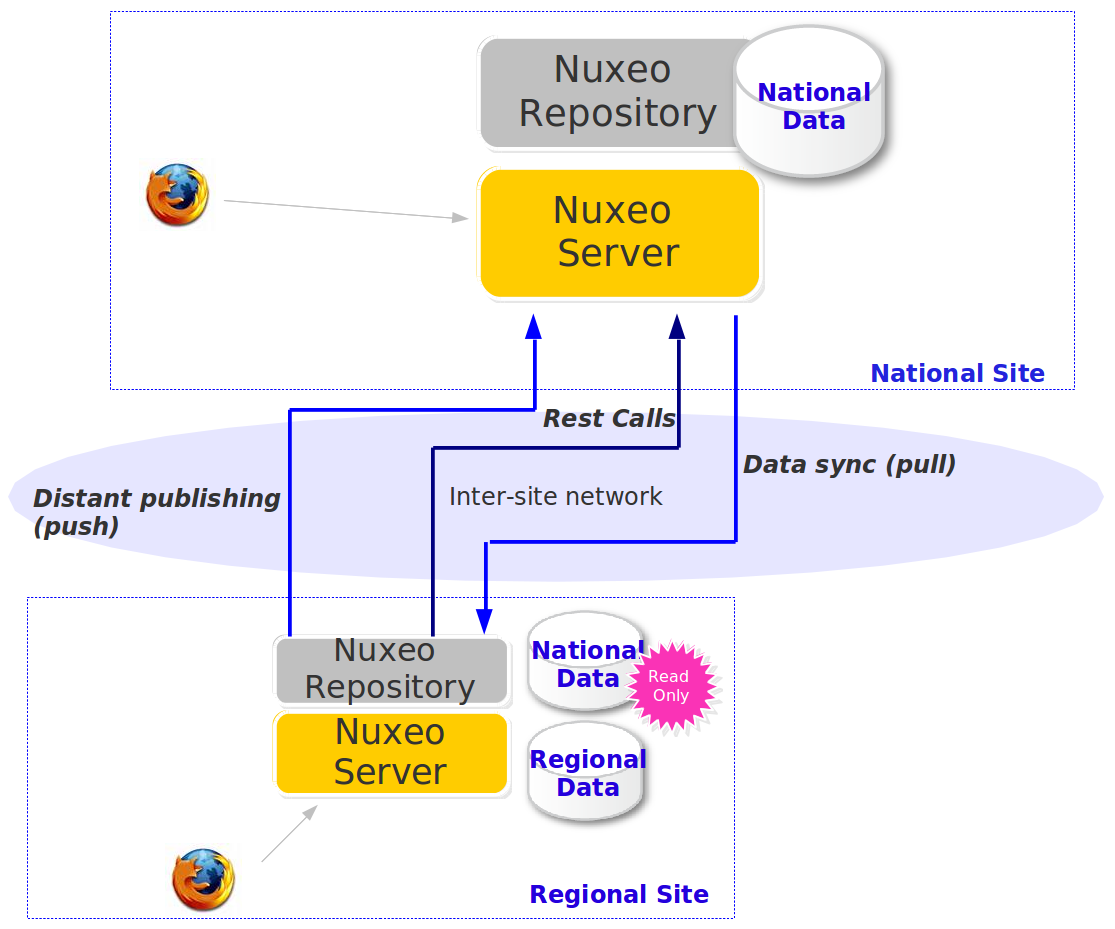
Read-Only Synchronization
The Nuxeo Platform being flexible, you can use several add-ons together to achieve a complex architecture:
- Use
nuxeo-platform-syncto create a read-only copy of a remote repository - Use remote plublisher to push information between two distant Nuxeo instances
- Use multi-repository support to segregate Local vs Central data