5 min tour of the Nuxeo Platform
Running the Nuxeo Platform
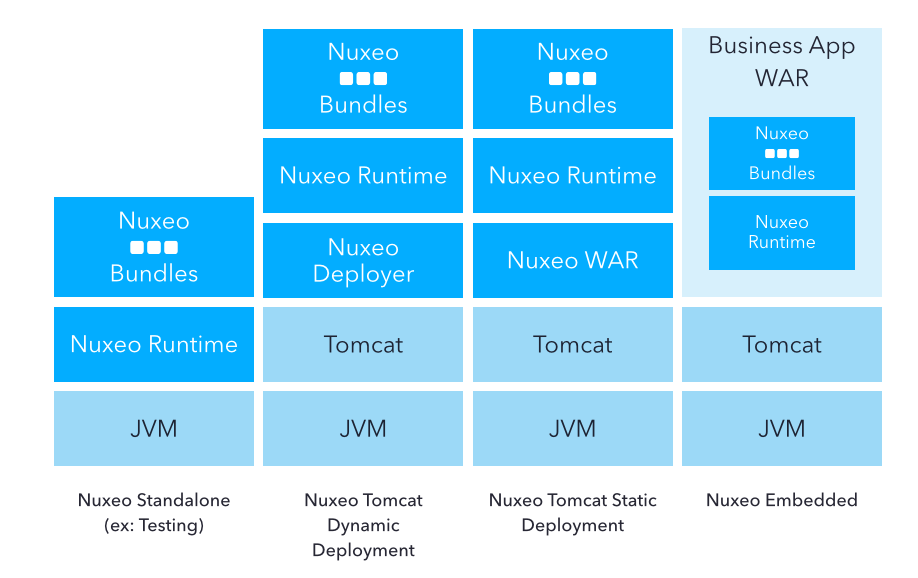
The Nuxeo Platform runs on top of the Java Virtual Machine.
There are several deployment options.
Bare Java Deployment
The Nuxeo Platform can be deployed directly on the JVM (i.e. without an application server).
The main use case for this deployment model is for testing, i.e. to deploy the Nuxeo Platform inside a JUnit test. But this solution can also be used to embed Nuxeo inside an existing Java application. In this case, the Nuxeo Runtime deployment may include JDBC DataSources, JTA transaction manager and a JCA Connector. The Nuxeo Runtime can also deploy an HTTP server if needed.
Application Server Deployment
The Nuxeo Platform can be packaged to run with Apache Tomcat. In that deployment scenario, Apache Tomcat provides:
- The deployment system (i.e. Tomcat triggers the Nuxeo deployment)
- The HTTP service and the servlet container
- The JDBC DataSources
The Nuxeo Platform will add a JTA Transaction Manager and a JCA Connector to Tomcat.
For more details about the Nuxeo deployment system, please refer to pages on deployment options.
About Nuxeo Platform Data
Data managed by the Nuxeo Platform includes:
- Documents:
- Metadata
- Binary Streams
- Users, Groups
- References data
- Indexes
Document Repository
The Nuxeo Document repository only focuses on managing Document persistence.
It covers:
- Hierarchy definition
- Security descriptors
- Metadata
- Binaries
- Indexes
The default configuration for Nuxeo Repository is to use a SQL Database and a Filesystem storage, as well as an Elasticsearch index (that can be removed from the architecture if necessary):
- Structured data are stored in a SQL Database:
- Hierarchy
- Security
- Metadata
- Binaries streams are stored in a "Filesystem like" storage called "BinaryStore".
The SQL Database can be:
- PostgreSQL
- Oracle
- MS SQL Server
- MySQL
For more details about Nuxeo Repository architecture, please see the VCS Pages.
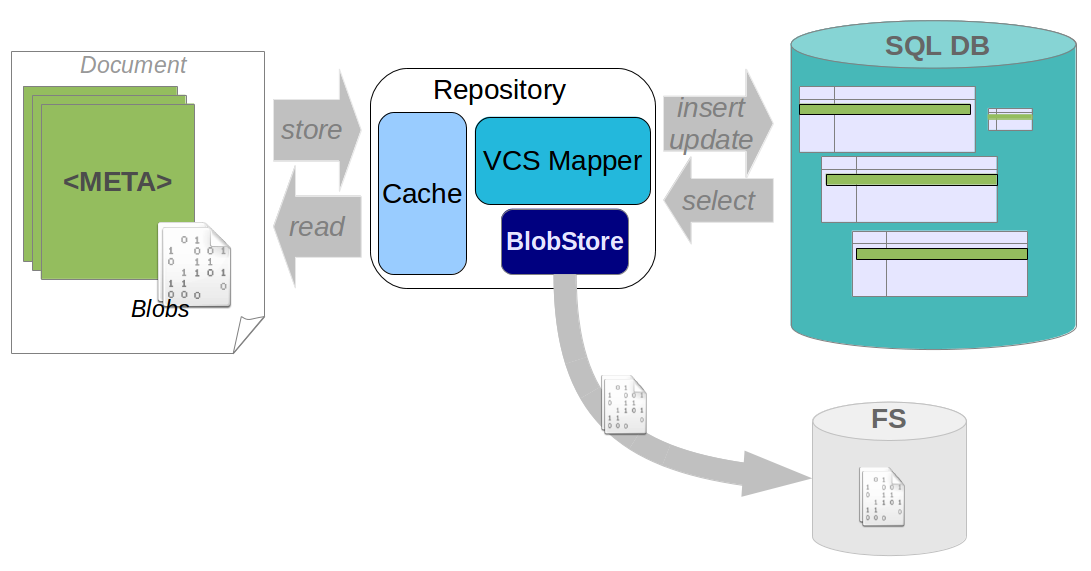
When the Nuxeo Repository access the database:
- It first goes through a cache.
- It uses a JDBC connection in the context of a Transaction.
- It can use a XA 2 phases commit transaction model.
The BinaryStore can be:
- A simple Filesystem
- A shared Filesystem (ex: NFS share or a NAS)
- A S3 bucket (with or without encryption)
For more details about Nuxeo Repository and BlobStore, please see the page File Storage.
Indexes
By default the Nuxeo Repository does handle keyword and full text indexing via the database.
However, external indexers can be plugged and in the 5.9.x Fast Track releases will come with an integration with Elasticsearch.
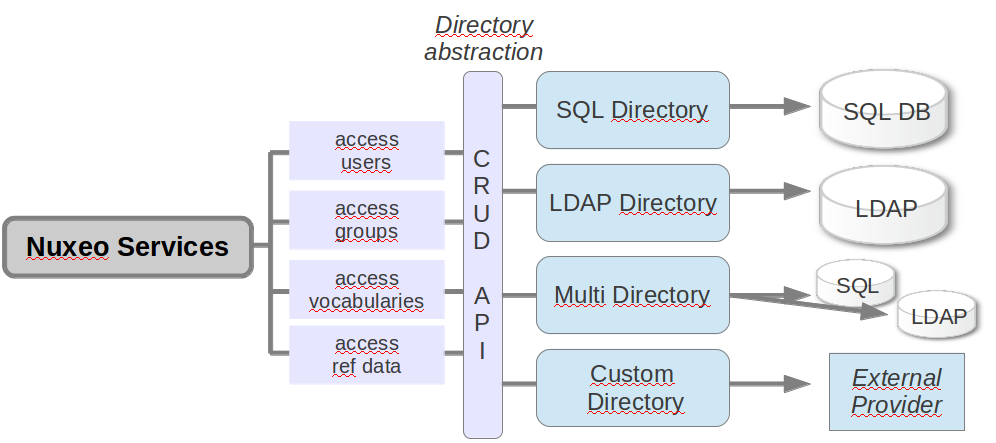
Non Document Data
For data that is more record oriented than document oriented, Nuxeo uses an abstraction called Directory system that allows to address Data in SQL, LDAP (or WebService).
The Directories are typically used for storing:
- Users
- Groups
- Lists of controlled values
By default, everything is bound to the same SQL database as the repository, but you can choose:
- To bind some directories to LDAP
- To bind some directories to an external database (use of XA mode is then required)
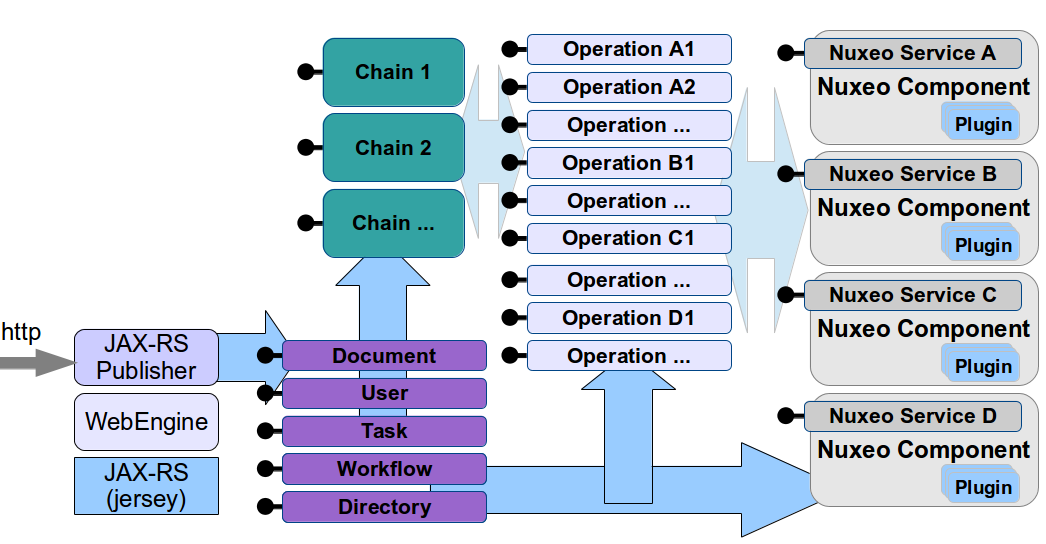
Integrating Nuxeo
Calling Nuxeo Services
Nuxeo services are exposed via an HTTP API called Nuxeo Content Automation.
Nuxeo resources (Documents, Users ...) are exposed via a REST API.
So, if your external application needs to call the Nuxeo Server you can use plain HTTP/JSon API to do the calls, or you can use one of the client libraries we provide.
Calling External Services from the Nuxeo Platform
You can extend the Nuxeo Platform to deploy your own Java Services.
A classical approach is to wrap your calls to external applications inside a Nuxeo Automation Operation.
Once you have this operation, you can use Nuxeo Studio to integrate for example SAP inside your Nuxeo application:
- Use your external service operations inside a Workflow.
- Bind your external service operation on new buttons in the UI.
- Associate your external service operation with events.
An interesting integration point is that you can hook operations or custom code on Nuxeo event bus.
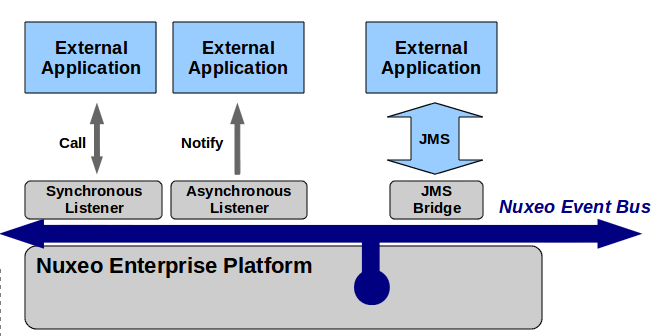
Data Integration
In addition of the native HTTP API, the Nuxeo Platform also provides solutions to import data inside the Nuxeo Platform.