- Data Capture - Import Strategies on Hyland University.
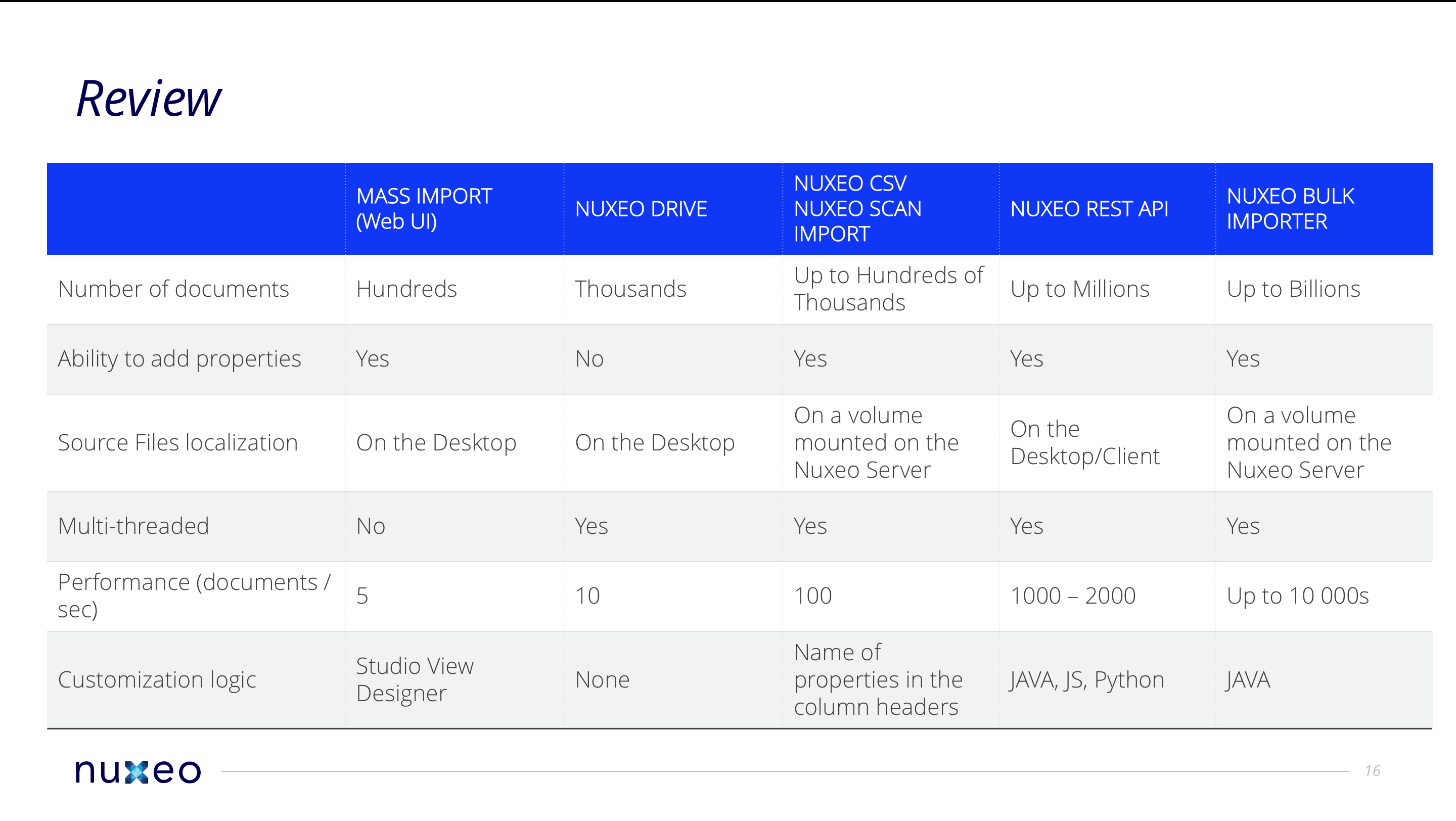
The Nuxeo Platform provides tools and APIs to import content:
- From 10s of documents to billions of them, with import rates such as 10,000s of documents per second
- With or without metadata
- Handling security, lifecycle and other system properties if necessary.
Those tools natively handle several formats to specify document properties:
- XML (one XML file per document or one for all documents)
- CSV (one line per document)
- Properties file (one property file per file to import for instance, or per folder)
Import Strategies
Importing content in the Nuxeo Platform means:
- Creating a document that will store the metadata and reference the binaries
- Importing the binaries (when there are some; some projects do not handle files, just business objects)
Creating Documents
There can be several strategies to create documents:
Use the REST API
- Pros: The simplest strategy. Can be done remotely as long as there is an HTTP access.
- Cons: The less performant, although proven rates of thousands of documents per seconds can be reached
Use the Java API server-side
- Pros: Transactional, multi-threaded and highly performant. It provides the ability to disable events processing and to bundle event processing
- Cons: A bit more complex to understand logics, requires to deploy a server-side plugin for any customization.
Fill in the database directly (SQL Scripts, MongoDB collections, ...)
- Pros: The most performant
- Cons: Requires knowledge of Nuxeo Platform internals. May break business logic as listeners are not handled, no event is fired in the repository. For instance, there won't be any audit, unless you fill the table at the same time. You still have to perform some additional tasks manually after that like rebuild full text, rebuild ancestors cache, rebuild read-ACLs
Importing Files
Similarly there can be several strategies to upload the binary content (the files):
Using the REST API
The REST API provides the batch endpoint to upload content, with ability to upload binaries by chunks and thus implement resume upload patterns.
- Pros: Can upload file from anywhere, just need an HTTP access
- Cons: Network becomes a strong limitation to import rates
Uploading them on a file system accessible from the Nuxeo server
- Pros: No network limitation as files may then be just "moved" to the right place (unless they are then stored on an object store in the cloud)
- Cons: It is not always easy to open access to the folder file system, so this solution cannot be seen as a generic strategy for central repository use case.
Moving the file right to the place it will then be stored by Nuxeo
May it be a file system binary store, an S3 binary store or an Azure Object store, it is always possible to drop the files at the right place to restrict operations.
- Pros: Most efficient way to do, especially when import is about very large multi-terabytes files.
- Cons: Not easy to handle as a general integration pattern, requires to compute hash of the file first.
Existing Import Tools
node.js Importer
Features
The node.js importer makes use of the REST API and provides you with additional services compared to the bare approach:
- Multi-threading
- Client-side browsing of a complete hierarchy of content (folders, subfolders and files)
Customization Language
JavaScript
Customization Logic
Fork and override a specific object implementation. It is quite easy to add a custom logic to start a workflow on the document at the same time, changing its lifecycle, or setting a custom ACL. A sample fork with custom rules is provided on GitHub.
Limitations
No out-of-the-box format for metadata values specification. Also not recommended if import rate is the critical factor, since data transit over HTTP/S.
Nuxeo Platform Importer
Features
The Nuxeo Bulk Document Importer is an importer framework provided as an addon that can be used to build custom importers. It relies on a standard crawler, transformer, writer schema. The Scan importer and CSV importer addons are using that framework (see next sections). It is the de-facto choice when you want to reach hyperscale numbers with importing content (up to 10 000s of documents per second). All you need to do is write your own Document Factory that will be in charge of the document creation logic in the repository. You can then easily launch the import controlling how many documents are done in a batch, how many batches per transaction, etc.
Customization Language
Java
Customization Logic
The importer framework offers many customization possibilities. You can read the Nuxeo Platform Importer documentation to learn more.
Limitations
Files must be available on a file system mounted on the Nuxeo server.
Nuxeo Scan Importer
Features
The Nuxeo Platform Scan Importer is a submodule of the importer framework and is typically used for the output of a digitalization chain. Nuxeo Platform Scan Importer listens to a given folder and will import all content referenced via XML files, with their metadata, etc. Scan importer also offers very advanced XML <--> documents mapping possibilities, with ability to use some automation processing during the import phase.
Customization Language
Java
Customization Logic
Scan Importer is configurable via XML extensions for the metadata mapping. The documentation provides links to simple and advanced use cases
Nuxeo CSV Importer
Features
Nuxeo CSV makes use of the importer framework and provides a UI to upload a CSV file whose content will be used to map columns values to properties of created documents.
Customization Language
Java
Customization Logic
See documentation.
Using the Bare REST API
You can straightly use the REST API and implement the importing logic you need from there.
Using the Bare Java API
You can use the CoreSession object in a server-side deployed custom Java component and implement the importing logic you need from there. We also provide a default import/export format for the repository with piping logic.