The Nuxeo Vision addon provides a gateway to computer vision services. Currently it supports the Google Vision API and Amazon Rekognition API. Other services can be easily integrated as they become available. These external services allow you to understand the content of an image by encapsulating powerful machine learning models. This gateway provides a wide range of features including shape recognition, auto-classification of images, OCR, face detection and more.
Installation and Configuration
This addon requires no specific installation steps. It can be installed like any other package with nuxeoctl command line or from the Update Center.
To install the Nuxeo Vision Package, you have several options:
- From the Nuxeo Marketplace: install the Nuxeo Vision package.
- From the Nuxeo server web UI "Admin / Update Center / Packages from Nuxeo Marketplace"
- From the command line:
nuxeoctl mp-install nuxeo-vision
Google Vision Configuration
- Configure a Google service account
- As of march 2nd, 2016, billing must be activated in your google account in order to use the Vision API
- You can generate either an API Key or a Service Account Key (saved as a JSON file)
- If you created a Service Account Key, install it on your server and edit nuxeo.conf to add the full path to the file:
org.nuxeo.vision.google.credential=[path_to_credentials_goes_here] - If you generated an API key, use the
org.nuxeo.vision.google.keyparameter:org.nuxeo.vision.google.key=[your_api_key_goes_here]
See https://cloud.google.com/vision/ for more information.
AWS Rekognition Configuration
- Configure a key/secret pair in the AWS console
- Check the FAQ to see in which regions the API is available
- Edit nuxeo.conf with the suitable information
org.nuxeo.vision.default.provider=aws org.nuxeo.vision.aws.region= org.nuxeo.vision.aws.key= org.nuxeo.vision.aws.secret=
Functional Overview
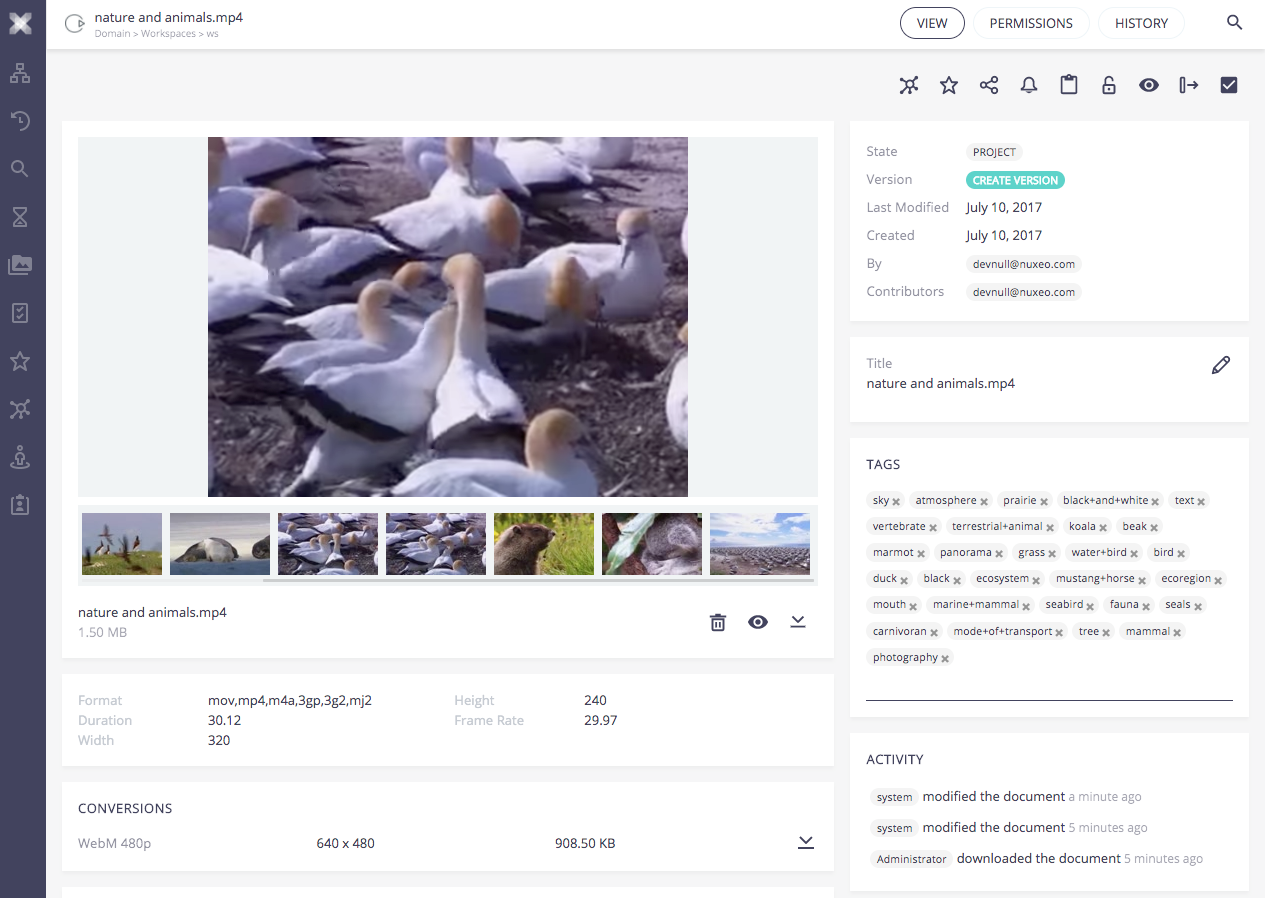
By default, the Computer Vision Service is called every time the main binary file of a picture or video document is updated. Classification labels are stored in the Tags property.
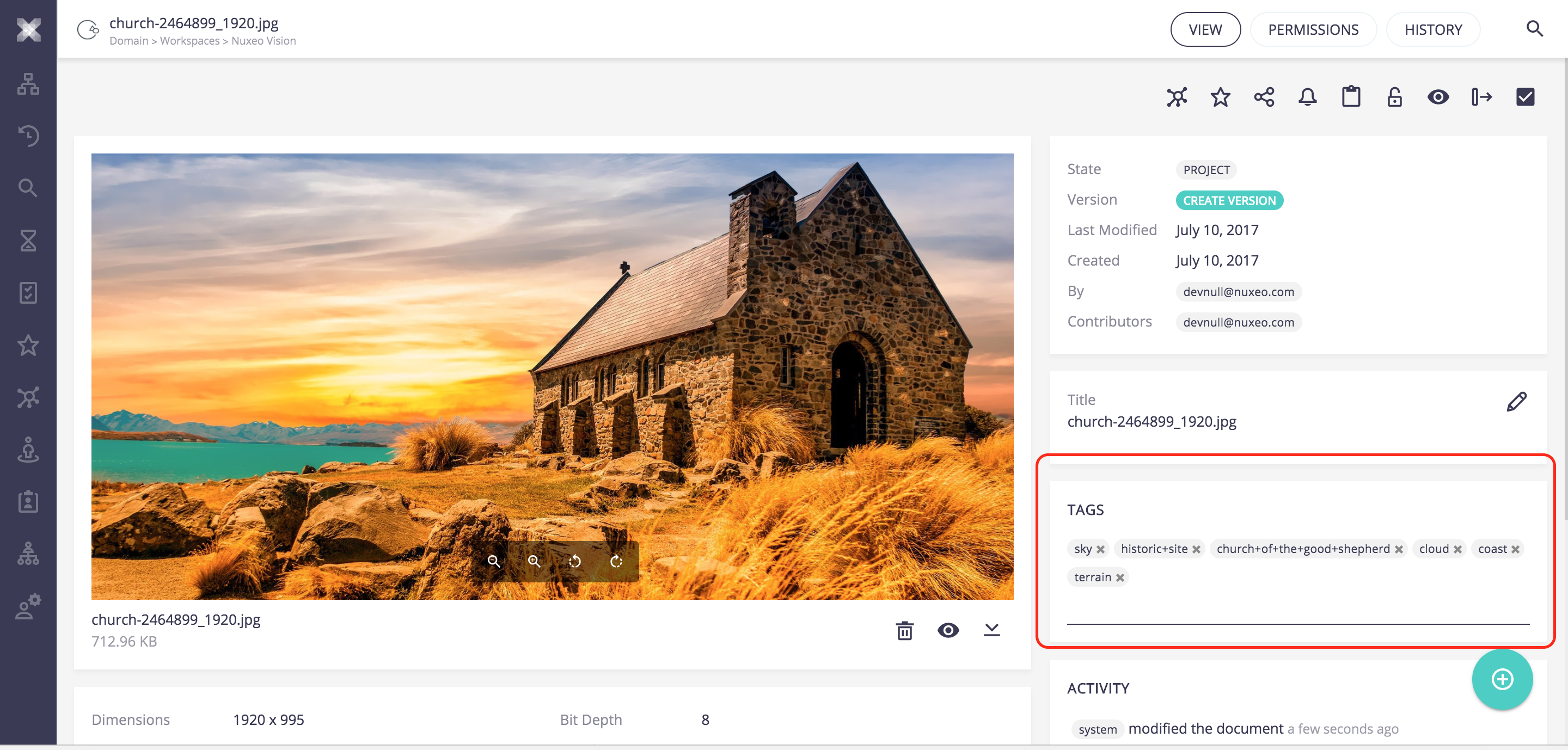
For videos, the platform uses the images of the storyboard.
Customization
Overriding the Default Behavior
The default behavior is defined in two automation chains which can be overridden with an XML contribution.
- Once the addon is installed on your Nuxeo instance, import the
VisionOpoperation definition in your Studio project. See the instructions on the page Referencing an Externally Defined Operation. - Create your automation chains and use the operation inside them. You can use the regular automation chains or Automation Scripting.
Create an XML extension that specifies that your automation chains should be used.
<extension target="org.nuxeo.vision.core.service" point="configuration"> <configuration> <defaultProviderName>${org.nuxeo.vision.default.provider:=}</defaultProviderName> <pictureMapperChainName>MY_PICTURE_CHAIN</pictureMapperChainName> <videoMapperChainName>MY_VIDEO_CHAIN</videoMapperChainName> </configuration> </extension>Deploy your Studio customization.
Disabling the Default Behavior
The default behavior can also be completely disabled with the following contribution:
<extension target="org.nuxeo.ecm.core.event.EventServiceComponent" point="listener">
<listener name="visionPictureConversionChangedListener" class="org.nuxeo.vision.core.listener.PictureConversionChangedListener" enabled="false"></listener>
<listener name="visionVideoChangedListener" class="org.nuxeo.vision.core.listener.VideoStoryboardChangedListener" enabled="false"></listener>
</extension>
Core Implementation
In order to enable you to build your own custom logic, the addon provides an automation operation, called VisionOp. This operation takes a blob or list of blobs as input and calls the Computer Vision service for each one. The list of all the available features can be found at https://cloud.google.com/vision/reference/rest/v1/images/annotate#Type.
The result of the operation is stored in a context variable and is an object of type VisionResponse.
Here’s how the operation is used in the default chain:
function run(input, params) {
var blob = Picture.GetView(input, {
'viewName': 'Medium'
});
blob = VisionOp(blob, {
features: ['LABEL_DETECTION'],
maxResults: 5,
outputVariable: 'annotations'
});
var annotations = ctx.annotations;
if (annotations === undefined || annotations.length === 0) return;
var textAndLabels = annotations[0];
// build tag list
var labels = textAndLabels.getClassificationLabels();
if (labels !== undefined && labels !== null && labels.length > 0) {
var tags = [];
for (var i = 0; i < labels.length; i++) {
tags.push(labels[i].getText().replace(/\s/g, '+'));
}
input = Services.TagDocument(input, {
'tags': tags
});
}
input = Document.Save(input, {});
return input;
}
Google Vision API Limitations
The API has some known and documented best practices and limitations you should be aware of. For example (as of December 2016):
- There is limitation to the size of the image you send to the API: "Image files sent to the Google Cloud Vision API should not exceed 4 MB". There also is a limitation when you send a list of images (max. 8MB). This is an important information to handle before requesting data. And this is why, if you look at the original chain, it actually takes the “Medium” conversion, which is a JPEG we can assume is always smaller than 4MB. You also should read the limitations in terms of maximum number of images/second, etc.
- Not all image formats are handled. TIFF for example is not handled.
- Amazon Rekognition doesn't provide text-recognition services (OCR)
Also, as it is a cloud service, these limitations will surely evolve, change, maybe depending on a subscription, etc.