The import / export service is providing an API to export a set of documents from the repository in an XML format and then re-importing them back.
The service can also be used to create in batch document trees from valid import archives or to provide a simple solution of creating and retrieving repository data. This could be used for example to expose repository data through REST or raw HTTP requests.
The import and export mechanism is extensible so that you can easily create your custom format for exported data. The default format provided by the Nuxeo Platform is described below.
Export Format
A document will be exported as a directory using the document node name for directory name and containing a document.xml file which holds the document metadata and properties as defined by document schemas. Document blobs, if any, are by default exported as separate files inside the document directory. There is also an option to export inlined blobs as Base64 encoded data inside the document.xml.
When exporting trees, document children are put as subdirectories inside the document parent directory.
Optionally each service in Nuxeo that stores persistent data related to documents, like the workflow, relation or annotation services, may also export their own data inside the document folder as XML files.
A document tree will be exported as directory tree. Here is an example of an export tree containing relations information for a workspace named workspace1:
+ workspace1
+ document.xml
+ relations.xml
+ doc1
+ document.xml
+ relations.xml
+ doc2
+ document.xml
+ relations.xml
+ file1.blob
+ doc3
+ document.xml
document.xml Format
Here is an XML that corresponds to a document containing a blob. The blob is exported as a separate file:
<document repository="default" id="633cf240-0c03-4326-8b3b-0960cf1a4d80">
<system>
<type>File</type>
<path>/default-domain/workspaces/ws/test</path>
<lifecycle-state>project</lifecycle-state>
<lifecycle-policy>default</lifecycle-policy>
<facet>Versionable</facet>
<facet>Publishable</facet>
<facet>Commentable</facet>
<facet>HasRelatedText</facet>
<facet>Downloadable</facet>
<access-control>
<acl name="inherited">
<entry principal="administrators" permission="Everything" grant="true"/>
<entry principal="members" permission="Read" grant="true"/>
<entry principal="members" permission="Version" grant="true"/>
<entry principal="Administrator" permission="Everything" grant="true"/>
</acl>
</access-control>
</system>
<schema xmlns:dc="http://www.nuxeo.org/ecm/schemas/dublincore/" name="dublincore">
<dc:valid/>
<dc:issued/>
<dc:coverage></dc:coverage>
<dc:title>test</dc:title>
<dc:modified>Fri Sep 21 20:49:26 CEST 2016</dc:modified>
<dc:creator>Administrator</dc:creator>
<dc:subjects/>
<dc:expired/>
<dc:language></dc:language>
<dc:rights>test</dc:rights>
<dc:contributors>
<item>Administrator</item>
</dc:contributors>
<dc:created>Fri Sep 21 20:48:53 CEST 2016</dc:created>
<dc:source></dc:source>
<dc:description/>
<dc:format></dc:format>
</schema>
<schema xmlns:file="http://www.nuxeo.org/ecm/schemas/file/" name="file">
<file:filename>error.txt</file:filename>
<file:content>
<filename>error.txt</filename>
<mime-type>text/plain</mime-type>
<encoding>UTF-8</encoding>
<digest>0ef7a41854fff8eecb4e8fb961628dce</digest>
<data>cd1f161f.blob</data>
</file:content>
</schema>
<schema xmlns:files="http://www.nuxeo.org/ecm/schemas/files/" name="files">
<files:files/>
</schema>
<schema xmlns:uid="http://project.nuxeo.com/geide/schemas/uid/" name="uid">
<uid:major_version>1</uid:major_version>
<uid:minor_version>0</uid:minor_version>
</schema>
<schema xmlns:common="http://www.nuxeo.org/ecm/schemas/common/" name="common">
<common:icon>/icons/text.gif></common:icon>
<common:size>71444></common:size>
</schema>
</document>
You can see that the generated document is containing one <system> section and one or more <schema> sections.
The system section contains all system (internal) document properties like document type, path, lifecycle state and access control configuration.
For each schema defined by the document type, there is a schema entry which contains the document properties belonging to that schema. The XSD schema that corresponds to that schema can be used to validate the content of the schema section. Anyway this is true only in the case of inlined blobs. By default, for performance reasons, blobs are put outside the XML file in their own file. So instead of encoding the blob in the XML file a reference to an external file is preserved: cd1f161f.blob.
Here is how the same blob will be serialized when inlining blobs (an option of the repository reader):
<schema xmlns:file="http://www.nuxeo.org/ecm/schemas/file/" name="file">
<file:content>
<filename>error.txt</filename>
<mime-type>text/plain</mime-type>
<encoding>UTF-8</encoding>
<digest>0ef7a41854fff8eecb4e8fb961628dce</digest>
<data>
b3JnLmpib3NzLnJlbW90aW5nLkNhbm5vdENvbm5lY3RFeGNlcHRpb246IENhbiBub3QgZ2V0IGNv
bm5lY3Rpb24gdG8gc2VydmVyLiAgUHJvYmxlbSBlc3RhYmxpc2hpbmcgc29ja2V0IGNvbm5lY3Rp
[...]
</data>
</file:content>
</schema>
Inlining Blobs
There is an option to inline the blob content in the XML file as a Base64 encoded text. This is less optimized but this is the canonic format to export a document data prior to XSD validation of document schemas.
Of course this is less optimized than writing the raw blob data in external files but provides a way to encode the entire document content in a single file and in a well known and validated format.
By default when exporting documents from the repository, blobs are not inlined. To activate the inlining option you must set call the method on the DocumentModelReader you are using to fetch data from the repository:
reader.setInlineBlobs(boolean inlineBlobs);
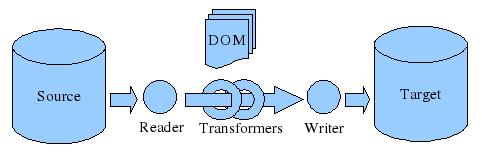
Document Pipe
An export process is a chain of three sub-processes:
- Fetching data from the repository
- Transforming the data if necessary
- Writing the data to an external system
In the same way an import can be defined as a chain of three sub-processes:
- Fetching data from external sources
- Transforming the data if necessary
- Writing the data into the repository
We will name the process chain used to perform imports and exports as a Document Pipe.
In both cases (imports and exports) a document pipe is dealing with the same type of objects:
- A document reader
- Zero or more document transformers
- A document writer
So the document pipe will use a reader to fetch data that will be passed through registered transformers and then written down using a document writer.
See the API Examples section for examples on how to use a Document Pipe.
Document Reader
A document reader is responsible for reading some input data and converting it into a DOM representation. The DOM representation is using the format explained in Document XML section. Currently dom4j documents are used as the DOM objects.
For example a reader may extract documents from the repository and output it as XML DOM objects. Or it may be used to read files from a file system and convert them into DOM objects to be able to import them in a Nuxeo repository.
To change the way documents are extracted and transformed to a DOM representation, you can implement your own document reader. Currently Nuxeo provides several flavors of document readers:
Repository readers - this category of readers is used to extract data from the repository as DOM objects. All of these readers are extending
DocumentModelReader:SingleDocumentReader- this one reads a single document given its ID and export it as a dom4j documentDocumentChildrenReader- this one reads the children of a given document and export each one as dom4j documentDocumentTreeReader- this one reads the entire subtree rooted in the given document and export each node in the tree as a dom4j documentDocumentListReader- this one is taking a list of document models as input and export them as dom4j documents. This is useful when wanting to export a search result for example.
- External readers used to read data as DOM objects from external sources like file systems or databases. The following readers are provided:
XMLDirectoryReader- reads a directory tree in the format supported by Nuxeo (as described in the Export format section). This can be used to import deflated Nuxeo archives or hand-created document directories.NuxeoArchiveReader- reads Nuxeo Platform exported archives to import them in a repository. Note that only zip archives created by the Nuxeo exporter are supported.ZipReader- reads a zip archive and output DOM objects. This reader can read both Nuxeo zip archives and regular zip archives (hand-made). Reading a Nuxeo archive is more optimized, because Nuxeo zip archives entries are added to the archive in a predefined order that makes it possible to read the entire archive tree on the fly without unzipping the content of the archive on the filesystem first. If the zip archive is not recognized as a Nuxeo archive the zip will be deflated in a temporary folder on the file system and theXMLDirectoryReaderwill be used to read the content.
To create a custom reader you need to implement the interface org.nuxeo.ecm.core.io.DocumentReader.
Document Writer
A document writer is responsible for writing the documents that exit the pipe in a document store. This storage can be a file system, a Nuxeo repository or any database or data storage as long as you have a writer that supports it.
The following DocumentWriters are provided by Nuxeo:
Repository Writers - write documents to a Nuxeo repository. They are useful to perform imports into the repository:
DocumentModelWriter- writes documents inside a Nuxeo Repository. This writer is creating new document models for each of the imported documents.DocumentModelUpdater- writes documents inside a Nuxeo Repository. This writer is updating documents that have the same ID as the imported ones or create new documents otherwise.
External Writers - write documents on an external storage. They are useful to perform exports from the repository.
XMLDocumentWriter- writes a document as a XML file with inlined blobsXMLDocumentTreeWriter- writes a list of documents inside a unique XML file with inlined blobs. The document tags will be included in aroottag:<documents> .. </documents>XMLDirectoryWriter- writes documents as a folder tree on the file system. To read back the exported tree you may useXMLDirectoryReader.NuxeoArchiveWriter- writes documents inside a Nuxeo zip archive. To read back the archive you may use theNuxeoArchiveReader.
To create a custom writer you need to implement the interface org.nuxeo.ecm.core.io.DocumentWriter.
Document Transformer
Document transformers are useful to transform documents that enter the pipe before they are sent to the writer. This way you can remove, add or modify some properties from the documents, or other information contained by the exported DOM object.
As documents are expressed as XML DOM objects you can also use XSLT transformations inside your transformer.
To create a custom transformer you need to implement the interface org.nuxeo.ecm.core.io.DocumentTransformer.
API Examples
Performing exports and imports can be done by following these steps:
Instantiate a new document pipe:
// create a pipe that will process 10 documents on each iteration DocumentPipe pipe = new DocumentPipeImpl(10);The page size argument is important when you are running the pipe on a machine different than the one containing the source of the data (the one from where the reader will fetch data). This way you can fetch several documents at once and improve performances.
Create a new document reader that will be used to fetch data and put it into the pipe. Depending on the data you want to import you can choose between an existing document reader implementation or you may write your own if needed:
reader = new DocumentTreeReader(docMgr, src, true); pipe.setReader(reader);In this example we use a
DocumentTreeReaderwhich will read an entire sub-tree from the repository rooted in 'src' document.The
docMgrargument represents a session to the repository, the 'src' is the root of the tree to export and the 'true' flag means to exclude the root from the exported tree.Create a document writer that will be used to write down the output of the pipe.
writer = new XMLDirectoryWriter(new File("/tmp/export")); pipe.setWriter(writer);In this example we instantiate a writer that will write exported data onto the file system as a folder tree.
Optionally you may add one or more document transformers to transform documents that enter the pipe.
MyTransformer transformer = new MyTransformer(); pipe.addTransformer(transformer);And now run the pipe.
pipe.run();
Exporting Data from a Nuxeo Repository to a ZIP Archive
File zip = File.createTempFile("MyFile", ".zip");
DocumentReader reader = null;
DocumentWriter writer = null;
try {
DocumentModel src = getTestWorkspace();
reader = new DocumentTreeReader(docMgr, root, true);
writer = new NuxeoArchiveWriter(zip);
// creating a pipe
DocumentPipe pipe = new DocumentPipeImpl(10);
pipe.setReader(reader);
pipe.setWriter(writer);
pipe.run();
} finally {
if (reader != null) {
reader.close();
}
if (writer != null) {
writer.close();
}
}
Importing Data from a ZIP Archive to a Nuxeo Repository
DocumentReader reader = null;
DocumentWriter writer = null;
try {
DocumentModel src = getTestWorkspace();
reader = new ZipReader(new File("/tmp/export.zip"));
writer = new DocumentModelWriter(docMgr, "import-domain/Workspaces/ws");
// creating a pipe
DocumentPipe pipe = new DocumentPipeImpl(10);
pipe.setReader(reader);
pipe.setWriter(writer);
pipe.run();
} finally {
if (reader != null) {
reader.close();
}
if (writer != null) {
writer.close();
}
}
Exporting a Single Document as an XML with Inlined Blobs
DocumentReader reader = null;
DocumentWriter writer = null;
try {
DocumentModel src = getTestWorkspace();
reader = new SingleDocumentReader(docMgr, src);
// inline blobs
((DocumentTreeReader)reader).setInlineBlobs(true);
writer = new XMLDocumentWriter(new File("/tmp/export.zip"));
// creating a pipe
DocumentPipe pipe = new DocumentPipeImpl();
// optionally adding a transformer
pipe.addTransformer(new MyTransformer());
pipe.setReader(reader);
pipe.setWriter(writer); pipe.run();
} finally {
if (reader != null) {
reader.close();
}
if (writer != null) {
writer.close();
}
}
REST Exposition of Core IO Export
CoreIO default XML exports as bound using Restlet framework that is still available even if this has been superseded via JAX-RS.
- Export a single document as XML:
http://NUXEO_SERVER/nuxeo/restAPI/{repository}/{uuid}/export?format=XML - Export a single document as XML + blobs in a ZIP:
http://NUXEO_SERVER/nuxeo/restAPI/{repository}/{uuid}/export?format=ZIP - Export a document tree as XML + blobs in a ZIP:
http://NUXEO_SERVER/nuxeo/restAPI/{repository}/{uuid}/exportTree