Functional Overview
Using Preview
The preview enables you to see an insight of your document.
The PDF files preview is leveraged by pdf.js by Mozilla. The preview of other file types are leveraged by the Nuxeo Platform preview module.
Several means to preview documents are available.
For office and PDF documents: Click on the
 icon in the document view.
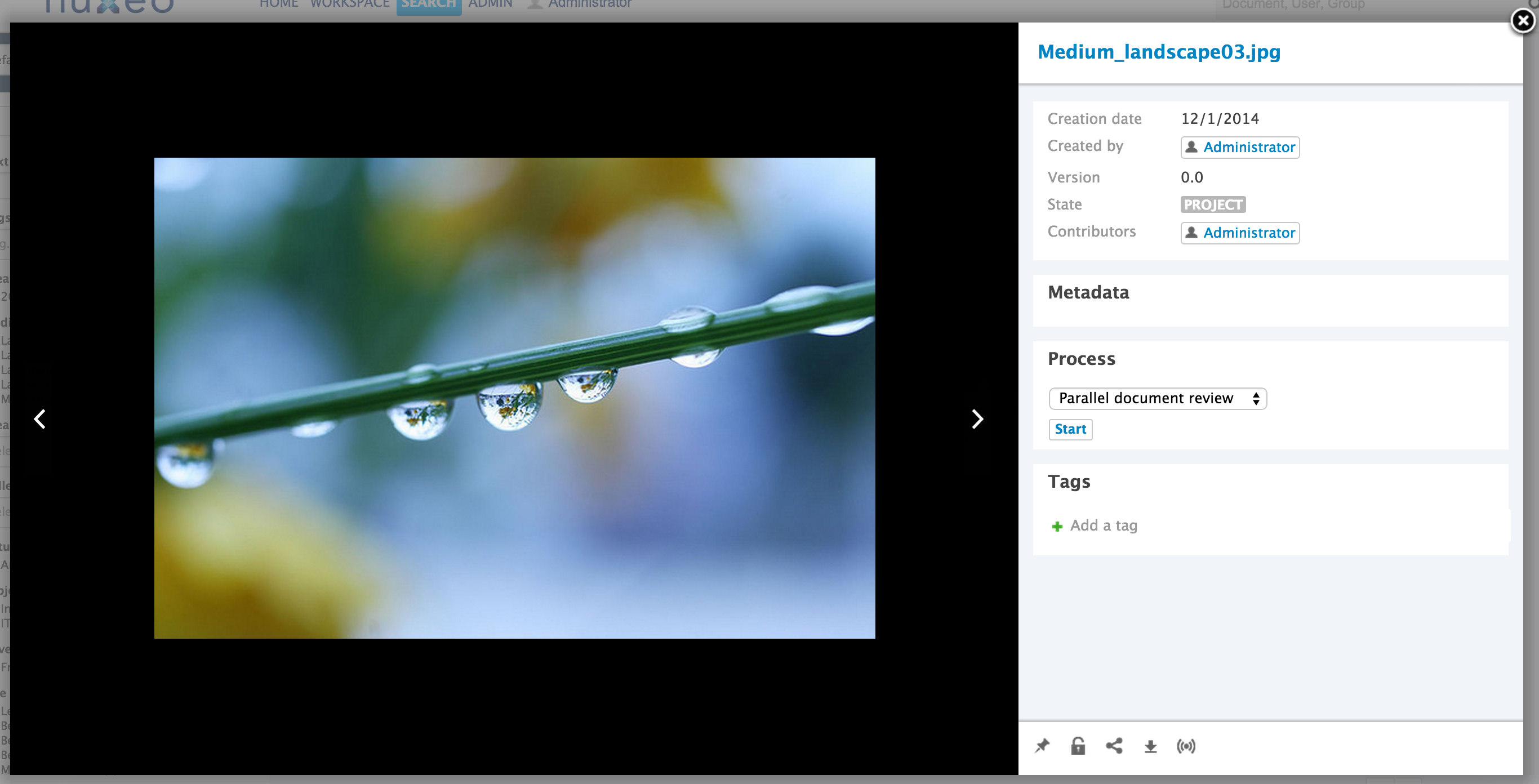
The preview opens in a popup window.
icon in the document view.
The preview opens in a popup window.

For all previewable documents, a Preview button (
icon) is available on the Document Actions section area (top right on the Web UI document view). On the JSF UI, you can find this on the Summary tab of a document, clicking on More > Preview.
The document preview is displayed in a popup window.

- On the JSF UI, you can also preview a document along with its main metadata on the Info-View pop-up, accessible from any thumbnail listing.
Supported Formats and Requirements
The table below shows for which file formats the preview is available. The installation of third-party software is required for some formats of the list below.
| File format | Preview supported |
|---|---|
| .ai | Yes |
| .doc | Yes |
| .docx | Yes |
| .eps | Yes |
| .html | Yes |
| .jpg | Yes |
| .odp | Yes |
| .ods | Yes |
| .odt | Yes |
| Yes | |
| .png | Yes |
| .ppt | Yes |
| .pptx | Yes |
| .psd | Yes |
| .tiff | Yes |
| .xls | Yes |
| .xlsx | Yes |
| .xml | Yes |
Installation and Configuration
For all document previews, make sure you installed the related software corresponding to your document types.
If you are running the Nuxeo Platform on macOS, you will fall into the bug NXP-18883. Until it is fixed, you will need to use the following contribution as a workaround:
<require>org.nuxeo.ecm.platform.commandline.executor.service.testContrib.magic2</require>
<extension target="org.nuxeo.ecm.platform.commandline.executor.service.CommandLineExecutorComponent"
point="command">
<command name="pdftohtml" enabled="true">
<commandLine>pdftohtml</commandLine>
<parameterString> -c -enc UTF-8 -noframes #{inFilePath} #{outDirPath}/index.html</parameterString>
<winParameterString> -c -enc UTF-8 -noframes #{inFilePath} #{outDirPath}\index.html</winParameterString>
<installationDirective>You need to install pdftohtml</installationDirective>
</command>
</extension>
Customization
You may want to check the following how-tos for customization:
Core Implementation
Technical Overview
When previewing a document, the logic executed goes through several layers (from end result to the most core part):
- Preview popup in Web UI and JSF UI: Adds a Preview popup that displays the preview inside an iframe, querying the Restlet preview URL for the current document.
A preview Restlet, that is in charge of handling caching logic when delivering the HTML preview for a given document. To achieve this we can user our REST API, using the blob and preview adapters as follows:
http://NUXEO_SERVER/nuxeo/site/api/v1/repo/{repo_id}/id/{document_id}/@blob/{previewfield}/@preview/{format}An example could be
http://localhost:8080/nuxeo/site/api/v1/repo/default/id/23d871d2-052a-4f58-8f90-4b07c5a074ea/@blob/file:content/@preview/image. It gets the HTML preview by getting theHtmlPreviewAdapterfrom the document model.The
HtmlPreviewAdapteris a standard Nuxeo Platform adapter, that is fetched usingdoc.getAdapter(HtmlPreviewAdapter.class). This adapter is a way to get access to the service below.The
PreviewAdapterManagerComponentand itsgetAdapter(DocumentModel doc)method that returns, depending on the document type ofdocand the contributions that have been made to extensionAdapterFactoryof this component, an object whose type implements the interface.
HtmlPreviewAdapter Details
The HtmlPreviewAdapter is an interface that is in charge of returning the preview blob (or list of blobs).
preview = targetDocument.getAdapter(HtmlPreviewAdapter.class);
List<Blob> previewBlobs= preview.getFilePreviewBlobs();
When no custom factory has been contributed for the given document type, the above mentioned service returns a ConverterBasedHtmlPreviewAdapter instance. This instance leverages the BlobHolder of the document to get the preview blob. If the document has no BlobHolder, it takes takes file:content or files:files. It uses the MimeTypePreviewer (see below) if the MIME type matches. If there is no MIME type match, the converter service is used to get a any2html conversion chain. (You can override/extend the MIME types that can benefit from this chain).
Some other adapters are contributed by default in the Platform, for pictures and notes. Contributing another adapter is, of course, possible. For instance, if you want to "merge" all the PDFs there are in the file:content and files:files properties of a custom "Report" type (or any other property) and preview all the content in one block. This custom logic could be written in an adapter. Or, if you want to generate the preview of a CAD (AutoCAD) document and need to get some linked files before doing your generation, this is where you would do it.
MimeTypePreviewer Details
The MimeTypePreviewer, as said above, may be used by the converter-based HtmlPreviewAdapter as a helper to build the HTML document. It was introduced to handle cases where the binary to preview is already in plain/text, XML or HTML, and we just need to either wrap it with <PRE> chunks and encode existing tags inside the content, or do other small string manipulations. Pragmatically, you may want to contribute a MimeTypePreviewer if you want to build your preview by doing a bit of HTML assembly with some custom logic, and that you want to use this logic on a per MIME type basis. You need to provide a mapping between a class that implements MimeTypePreviewer and a regular expression that can be validated by the MIME type of the targeted blob to preview.
Note that it is by default called only from the converter-based HtmlPreviewAdapter. If you contribute your own adapter and also want to benefit from this logic, you need to call inside your HtmlPreviewAdapter implementation. The following extract of Nuxeo code illustrates how to use it:
String srcMT = blob.getMimeType();
MimeTypePreviewer mtPreviewer = Framework.getService(PreviewAdapterManager.class).getPreviewer(srcMT);
if (mtPreviewer != null) {
blobResults = mtPreviewer.getPreview(blob2Preview, adaptedDoc);
return blobResults;
}
ZipFile Handling Details
When previewing a zip, the files it contains are listed. The displayed filenames are decoded as UTF-8. The following exception can be raised at ZipFiles instanciation if the underlying zip was encoded in a charset different from UTF-8 containing non-ASCII characters:
ZipException: invalid CEN header (bad entry name)
Character set detection is at best an imprecise operation. Apache Tika
Decoding files can't be done by looping over a list of available charsets as some may work but give partial results (missing characters for example). To work around this, a fallback charset mechanism is provided to decode zips which cause issues while keeping the whole platform working in UTF-8.
This allows you to provide a single, specific charset which should be the right one to read the zip.
This charset can be configured via the ConfigurationService:
<?xml version="1.0"?>
<component name="org.nuxeo.ecm.zip.file.reader.fallback.config">
<extension target="org.nuxeo.runtime.ConfigurationService" point="configuration">
<property name="org.nuxeo.ecm.zip.file.reader.charset.fallback">cp850</property>
</extension>
</component>