This page covers the principles and components that can be included in a production-ready Nuxeo cluster architecture.
Cluster Basics
Setting up a Nuxeo cluster consists of answering two main constraint types, independently or combined:
- Scalability - The setup has to scale easily without sacrificing performances to adapt to a varying load.
- High Availability - When something goes wrong, you should be able to restore service quickly, losing as little data as possible in the process.
In order to scale out and provide high availability (HA), Nuxeo provides a simple clustering solution. When cluster mode is enabled, you can have several Nuxeo server nodes connected to the same components, and you can then simply add more Nuxeo server nodes if you need to serve more requests.
This diagram represents the logical architecture for a Nuxeo cluster. It contains the following components:
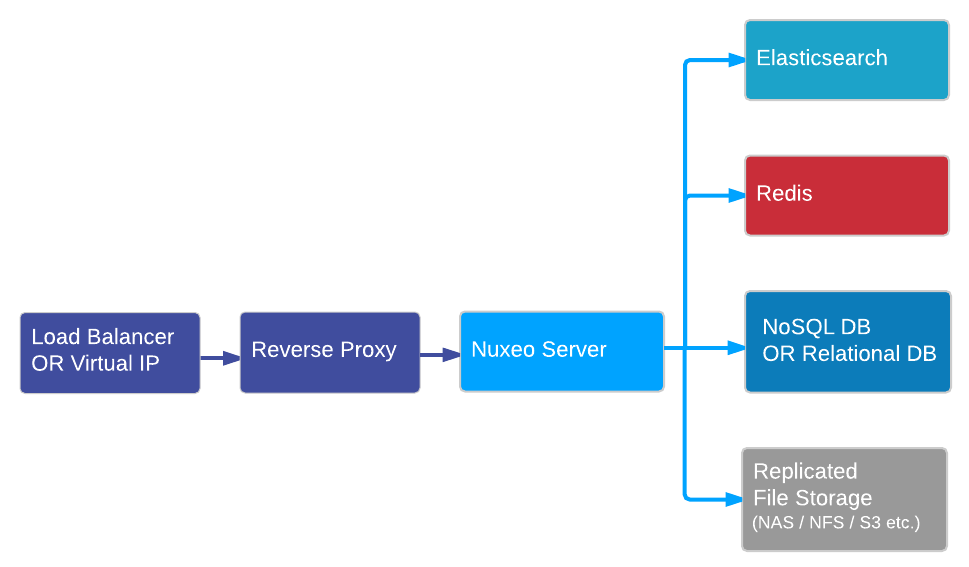
- Load balancers,
- Reverse proxies,
- A Nuxeo server cluster,
- A database cluster Nuxeo can connect to,
- An Elasticsearch cluster,
- A Redis cluster and/or a Kafka cluster
- A file system where binaries will be stored.
We will explain the role of each component below.
Load Balancers
Load balancers are used to allocate the load between Nuxeo nodes. They can be configured to redirect particular queries to specific nodes. This can be interesting in the following use cases:
- When using Nuxeo Drive, to make sure that even during an unexpected activity peak, only specific nodes can possibly slow down, while keeping usual performances for the other activities.
- When using adapted hardware with nodes dedicated to heavy processing, such as video conversion.
Load balancing can be managed by software or hardware, but in all cases (even if you use Nuxeo as a bare server without a UI) the only constraint we ask for is to have a load balancer configured with sticky sessions.
For high availability, two load balancers are necessary.
Reverse Proxy
A reverse proxy is used to avoid users from accessing the Nuxeo server directly. One simple rule you have to follow is that on a production setup, your Nuxeo server should never be exposed directly. Setting up a reverse proxy brings many benefits to performance and security aspects:
- HTTPS/SSL encryption
- HTTP caching
- URL rewriting
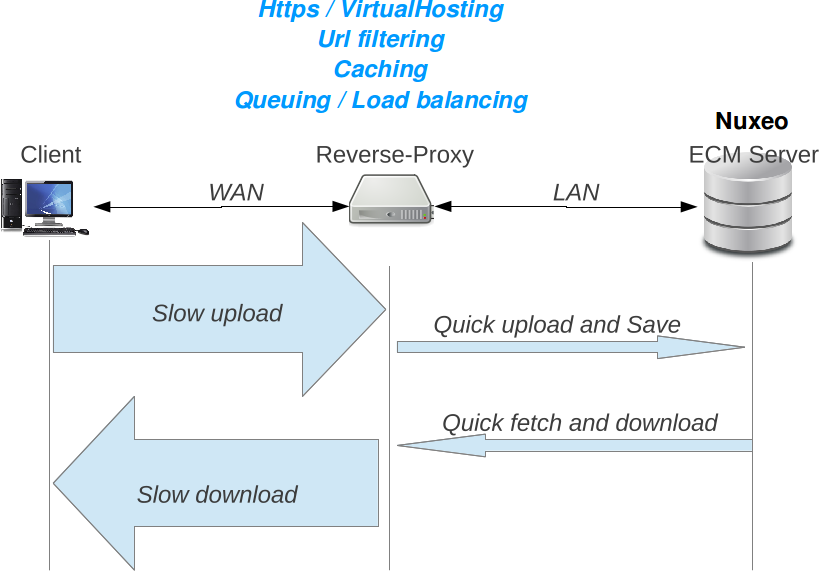
Additionally, when some clients use a WAN to access the server, the reverse proxy can be used to protect the server against slow connections that may use server-side resources for a long time. You may refer to the reverse proxy configuration for more details.
Nuxeo Server
Nuxeo Server can be installed in a variety of ways, including a docker container, a VM image, a debian repository, or a simple cross-platform zip file. It is distributed in a prepackaged Tomcat server that includes Nuxeo, a transaction manager (JTA) and a pool manager (JCA). The WAR file is generated dynamically upon each Nuxeo server restart, allowing easy configuration changes and customization deployment. Further information on this subject can be found in the Understanding Bundles Deployment documentation.
Nuxeo Server can be deployed anywhere, including as an embedded tool. Having a lightweight embedded Nuxeo server is a solution commonly used for unit testing or offline access. For the latter, the Nuxeo server would be embedded client side (for example, on a tablet) to allow offline access, and would synchronize with a central Nuxeo server when going back online.
For a high availability cluster, a minimum of two Nuxeo server nodes is required.
Database
The database is a core component for your Nuxeo cluster infrastructure, since it will store the document hierarchy, all document properties, and will be used as well for various queries. Nuxeo supports many databases, both NoSQL and relational ones. Among them, MongoDB and PostgreSQL currently provide the best overall performances for Nuxeo usage.
Each database has its own solutions for high availability, therefore we may not recommend a specific option here. You may however refer to our database configuration documentation for further details.
Elasticsearch
Elasticsearch is used to relieve the database from the costliest operations:
- It keeps indexes on the documents in order to allow blazingly fast searches and modern search options like realtime filtering (AKA facets), even on very high volumes.
- It stores the document's audit log. Since every operation on a document in Nuxeo is stored for possible audit purposes, the corresponding table would grow very rapidly and possibly reach millions of tuples when stored in the database. Using Elasticsearch, this is not a problem anymore.
- It scales horizontally and provides constant performance even with growing content size.
Elasticsearch remains an optional component and can be deactivated if needed. But except for some specific use cases where installation size and setup steps highly matter (for example, when embedding a Nuxeo server), it is highly recommended to take advantage of it. Refer to the Elasticsearch setup documentation for more information.
Imagine that your cluster gets cut in half: 2 nodes on side A cannot communicate anymore with the third node on side B. In this situation, if the master node is the one isolated on side B, failover can be achieved properly because a majority (the 2 nodes on side A) can elect a new master node between them and keep service available.
If you had 4 nodes in the same situation, service wouldn't be available anymore because a majority could not be obtained when voting. This is known as the split-brain problem. This also means that the minimum number of nodes to obtain high availability is 3.
Redis And/Or Kafka Cluster
When running in cluster mode, the Nuxeo nodes needs to communicate so the following services work in a distributed way:
- The WorkManager can distribute its Works among nodes and share a common state
- Nuxeo Stream and the Bulk Service distribute processing among nodes and handle failover
- The KeyValue Store enabling distributed cache and a shared Transient Store
- The PubSub Service can publish messages to all nodes and is used for cache invalidation
Before Nuxeo 9.10, Redis was the only option for all the available distributed services:
| Nuxeo 8.10 | WorkManager | KeyValue Store | PubSub Service |
|---|---|---|---|
| Redis | Yes | Yes | Yes |
Since Nuxeo 9.10 and the introduction of Nuxeo Stream, there are more choice and it is even possible to not use Redis when using Kafka and MongoDB:
| Nuxeo 9.10 | WorkManager | Nuxeo Stream | KeyValue Store | PubSub Service |
|---|---|---|---|---|
| Redis | Yes | No | Yes | Yes |
| Kafka | Yes | Yes | No | Yes |
| MongoDB | No | No | Yes | No |
Since Nuxeo 10.10, there are KeyValue store implementations for SQL backend. We strongly recommend the usage of Kafka to have a highly reliable Bulk Service.
| Nuxeo 10.10 | WorkManager | Nuxeo Stream/Bulk Service | KeyValue Store | PubSub Service |
|---|---|---|---|---|
| Redis | Yes | No | Yes | Yes |
| Kafka | Yes | Yes | No | Yes |
| MongoDB | No | No | Yes | No |
| SQL DB | No | No | Yes | No |
Redis
As seen above, Redis can be used for the WorkManager, KeyValue Store and PubSub service.
When a Redis instance or cluster is set up, you can safely stop your Nuxeo server nodes anytime without being worried about losing these jobs in the process.
Keep in mind that Redis is always limited by its available memory which can be a problem on a mass operation.
For high availability, a Redis cluster with a minimum of three nodes is required (for the same reasons as Elasticsearch).
Two options exist to handle automatic failover:
Redis Sentinel
Redis Sentinel is the open-source option to provide automatic Redis node failover. Nuxeo server's API has been adapted to be used with Redis Sentinel, and some of our customers happily use it in production. Before choosing it though, you need to know that RedisLabs (creators of Redis) does not officially support it, which means that in case of a problem we will not be able to provide support either.
Redis Enterprise
Redis Enterprise is our recommendation for a high availability Redis cluster, as it gets support from RedisLabs. You may visit the RedisLabs website for more information about the product.
Kafka
Since Nuxeo 10.10 Kafka is recommended in cluster mode so the Bulk Service can be distributed and handle failover between Nuxeo nodes.
When used as WorkManager implementation you can safely stop a Nuxeo node anytime without being worried of losing any processing.
When the KeyValue store relies on the repository's backend, you don't need a Redis cluster anymore.
Kafka requires few resources and it is limited only by the available disk space.
For high availability Kafka needs to be deployed in cluster.
File System
Nuxeo stores binaries attached to the documents on a file system by default. That can be a shared file system, a NAS, an Amazon S3 bucket or its Microsoft Azure equivalent, etc. More options are available depending on your target deployment. This is described in the Storage Alternatives section below.
Storage Alternatives
Nuxeo is pluggable so that it can be adapted to different deployment environments and use cases.
This means you can define where you want to manage your data, and because the answer may depend on the type of data. Nuxeo provides different types of backend for different types of storage.
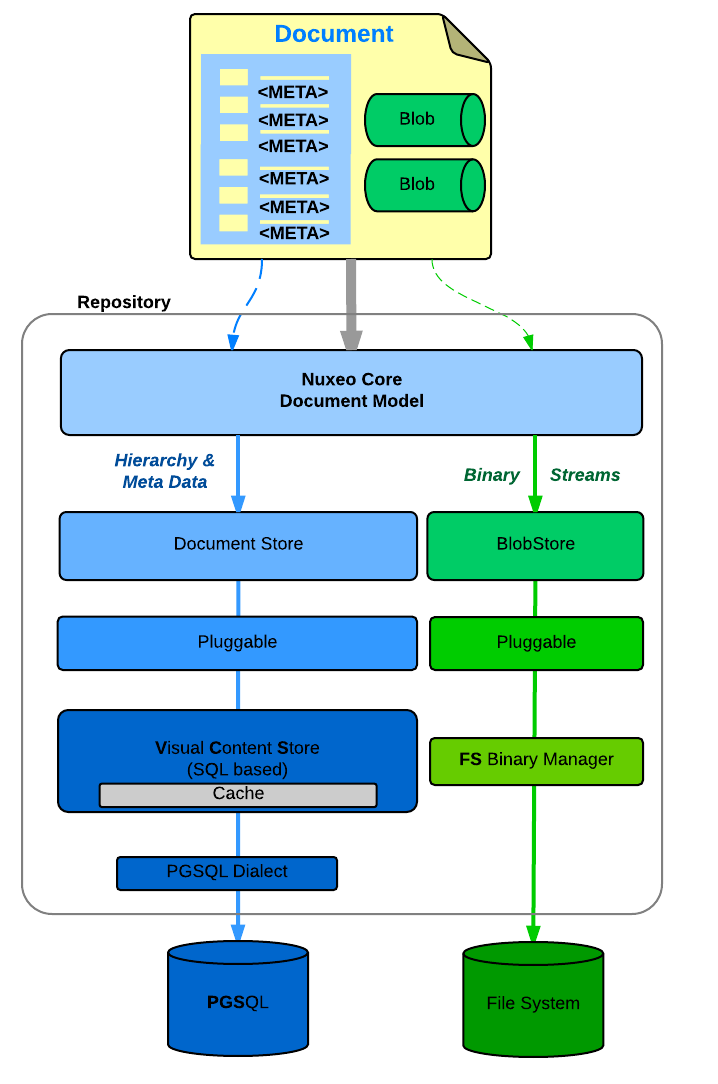
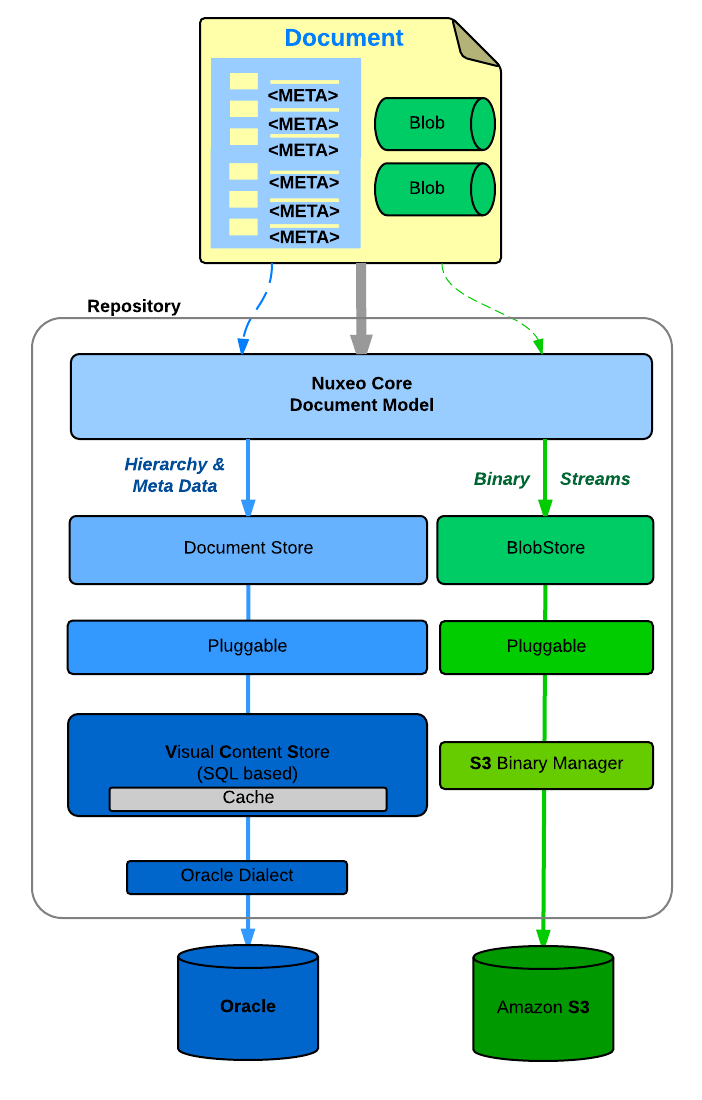
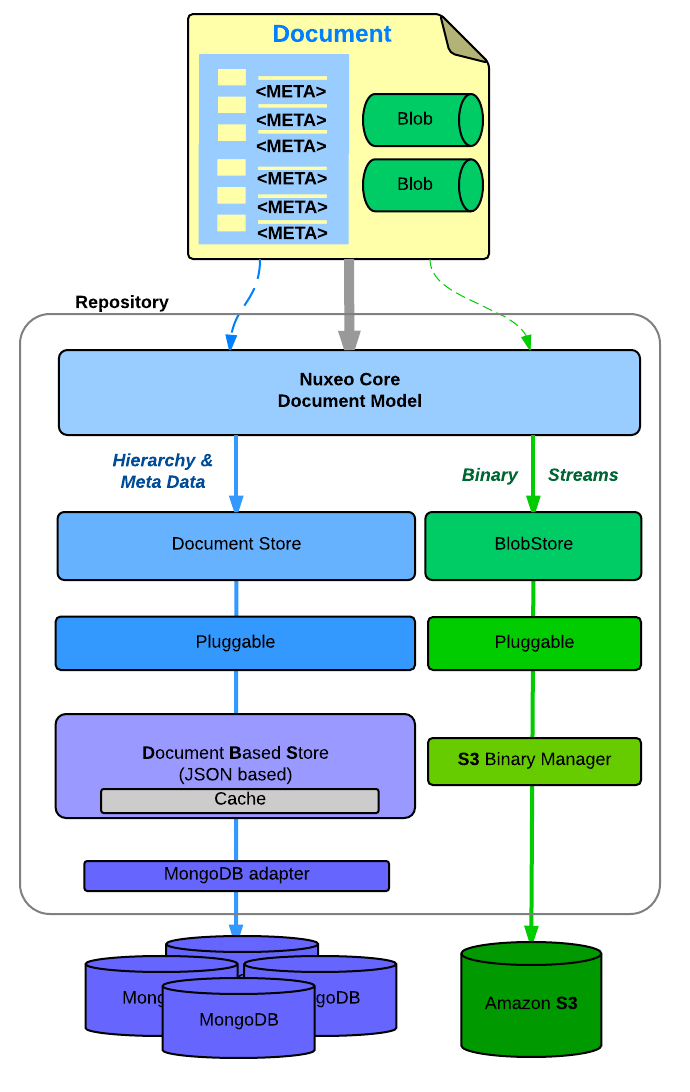
Document Storage
You can configure:
- Where you store the document metadata and hierarchy
- SQL Database (PostgresSQL, Oracle, MSSQL, MySQL, Amazon RDS)
- MongoDB
- Where you store the binary streams (the files you attach to documents)
- Simple FileSystem
- SQL Database
- S3, Azure
- Leveraging Content Delivery Networks for caching content securely all around the globe.
|
|
|
| PosgreSQL + FileSystem | Oracle + S3 | MongoDB + S3 |
Indexes
You can also select where you store the indexes (including the full-text)
- SQL Database
- Elasticsearch
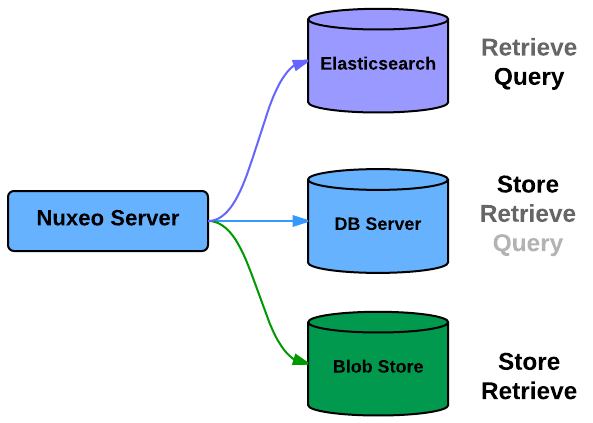
Since 6.0, the default configuration uses Elasticsearch.
Others
In the same logic, you can choose:
- Where you store the caches and transient data
- In Memory (per instance basis)
- Redis (shared memory)
- Where you store Users and Groups
- SQL Database
- LDAP or Active Directory
- Mix of both
- External system
- Where you store the audit log entries
- In Elasticsearch
- In the database