Architecture Description
In this architecture:
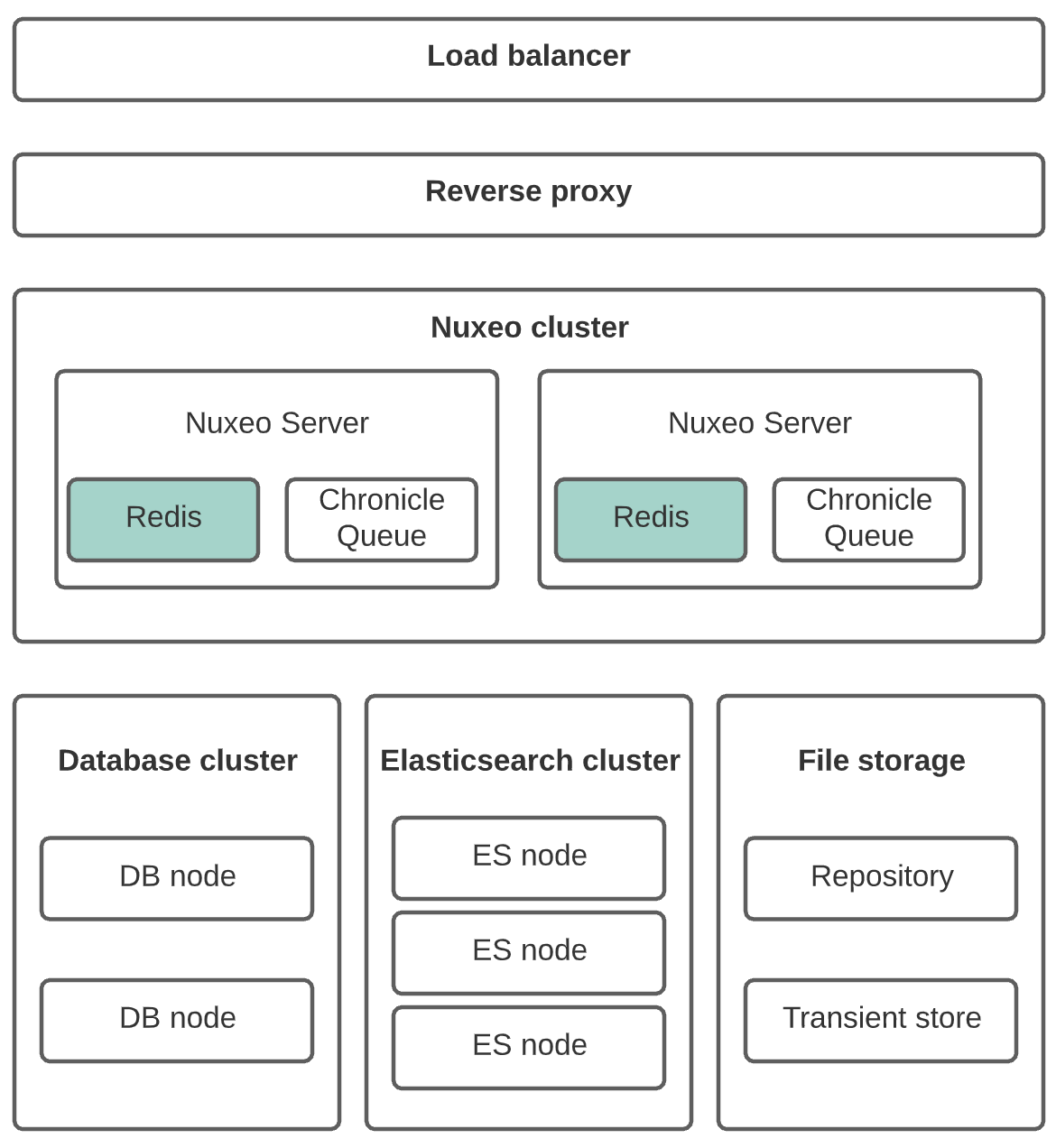
- A load balancer with sticky sessions is used.
- A total of two machines are prepared for the application cluster. Each machine holds a Nuxeo server node, a Redis node, and a reverse proxy. More machines can be added later for scalability purpose.
- Since we have two Redis nodes, we take advantage from it to configure Redis in master / slave mode.
- An Elasticsearch cluster with at least 3 nodes.
- A database cluster with at least 2 nodes.
- Chronicle Queue as the default implementation for Nuxeo Stream.
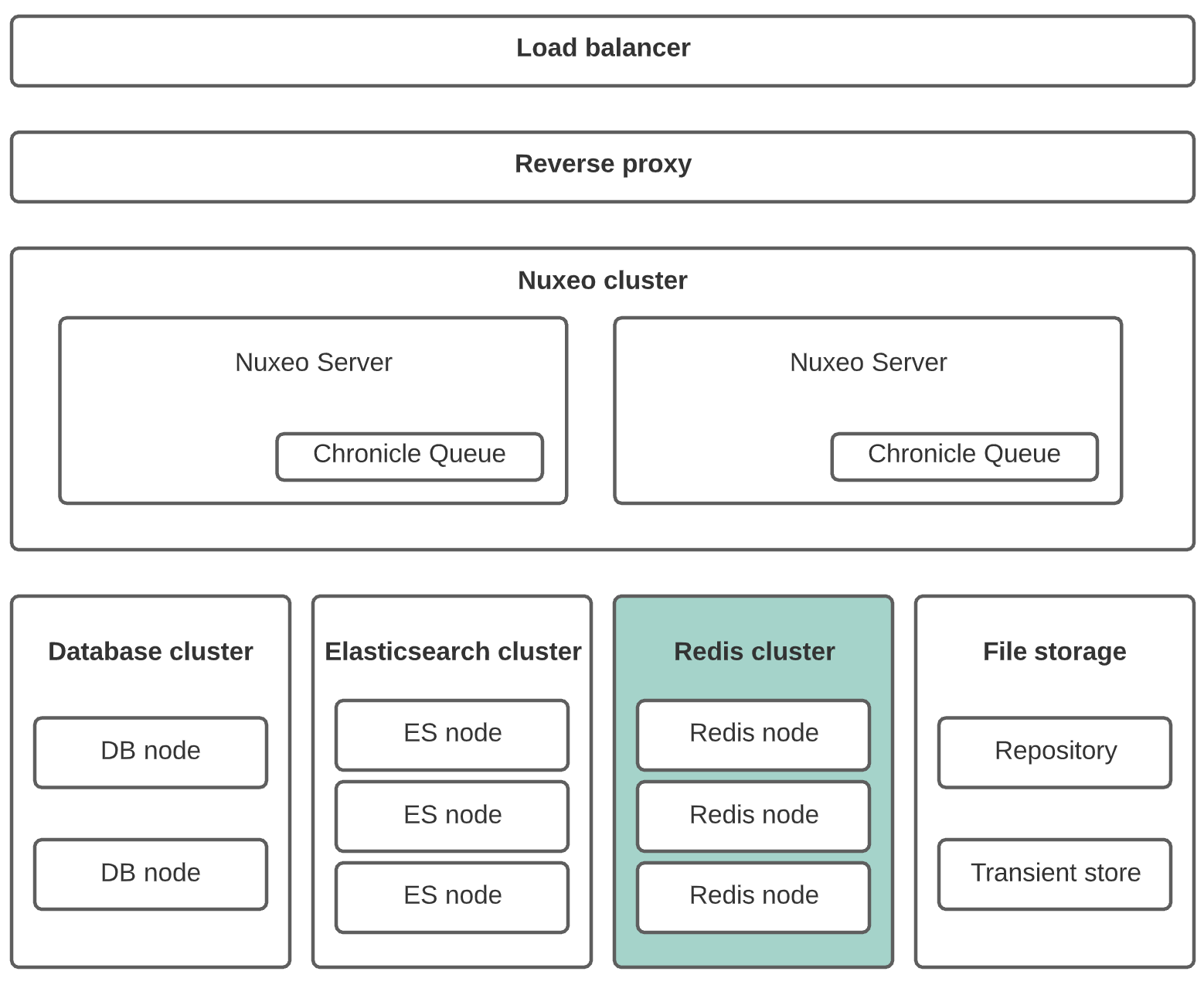
This architecture can be improved by externalizing the Redis node inside a specific cluster:
Limitations
- As detailed in the asynchronous processing component description, Chronicle Queue doesn't provide a distributed and fault tolerant architecture: in case of failure, scheduled jobs might be lost.
- Chronicle Queue has to be deployed on the Nuxeo server and consumes JVM when a lot of work is queued, with possible impacts on the Nuxeo Server performance.
- Using Redis to manage the WorkManager implies that the job queues are in the JVM memory. Consequently, stacking a lot of jobs will consume JVM Memory. In cluster mode, each Nuxeo node maintains its own queue so when a Nuxeo server is restarted, all the queued jobs are lost.
→ Jump to the Compact architecture with Kafka to:
- Remove Redis and Chronicle Queue limitations
- Benefits from Kafka advantages