This page details standard architecture options to deploy a Nuxeo cluster.
High Availability Production Architecture
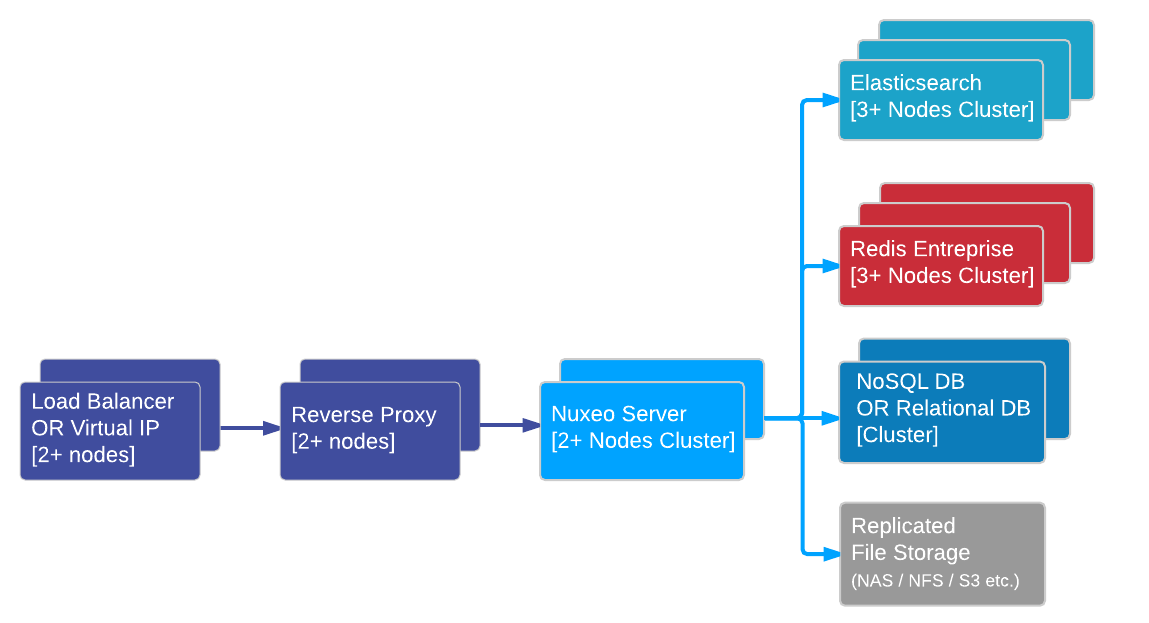
The standard Nuxeo cluster architecture providing high availability is composed of:
- Two load balancers in front with sticky sessions handling incoming requests and directing them to the appropriate Nuxeo server nodes.
- A reverse proxy to protect each Nuxeo server node (usually Apache or Nginx).
- At least two Nuxeo server nodes. You can add any number of nodes to scale out performances.
- At least three nodes for the Elasticsearch cluster, same for Kafka and Redis if used. Contrarily to Nuxeo server nodes, these components always require an odd number of nodes to avoid the split-brain problem, which means you need to add nodes by batches of two minimum when wishing to scale out performances.
- A database system providing high availability. Each solution has its own options for this, therefore we can't go into further details here.
- A shared file system that is used to store binary files.
Deploying in Cloud or Container Based Deployment
This diagram translates perfectly to an on-premise deployment using a container-based technology like docker and we provide a ready-to-use docker image for Nuxeo Server.
Nuxeo Platform also makes it easy to deploy in the cloud since:
- We are standard-based
- The pluggable component model (extension points) allows you to easily change backend implementation when needed.
For example, considering Amazon AWS as a possible cloud infrastructure provider:
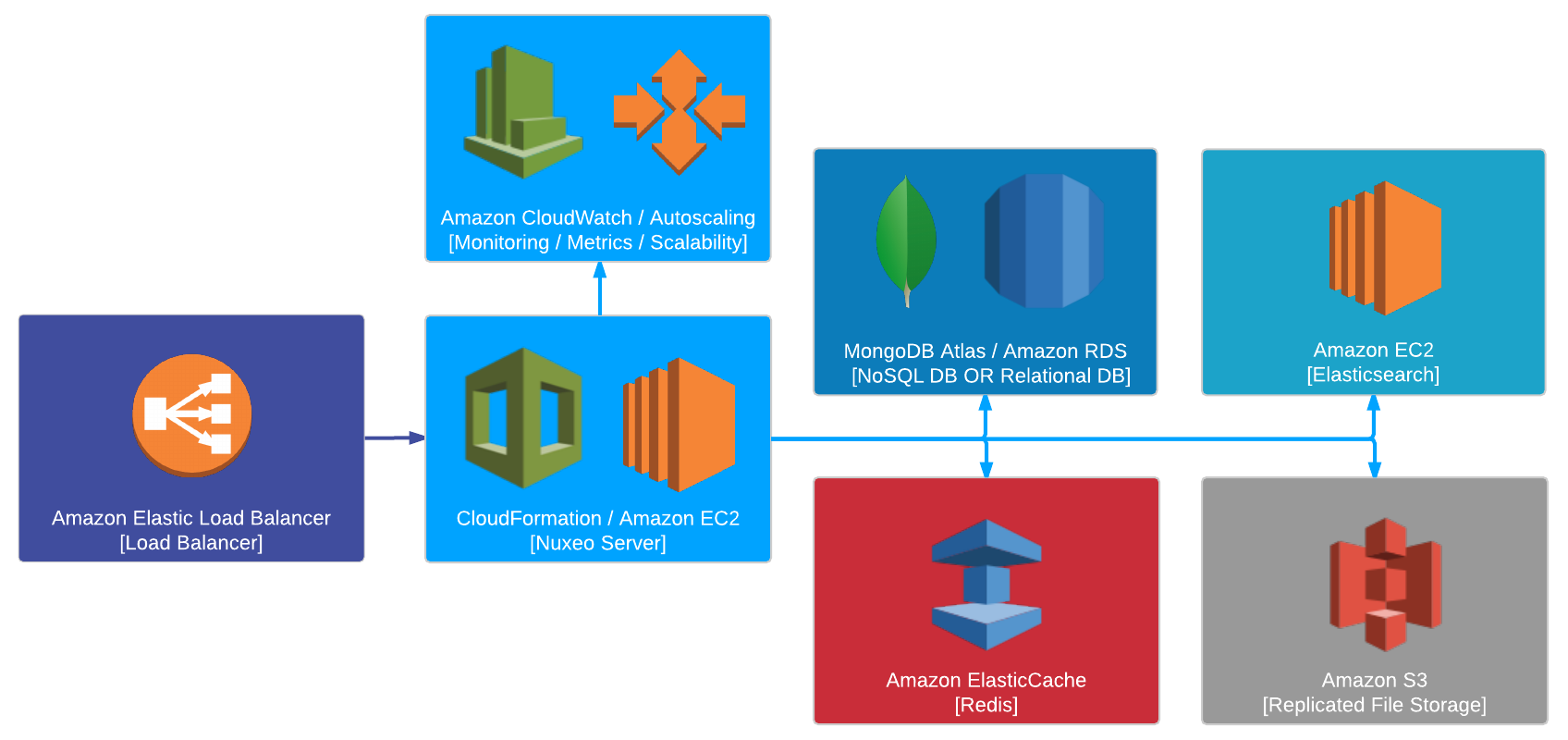
- The AWS ELB would be used for load balancing.
- EC2 instances can be used for Elasticsearch cluster nodes too. The Amazon ElasticCache service does not provide the required APIs at this point to allow us to have a completely managed cluster.
- Amazon ElasticCache can be used for a managed Redis cluster. Another option is to have a cluster hosted and managed by RedisLabs.
- Amazon Managed Streaming for Kafka (MSK) is an option for Kafka if it is available in your AWS region.
- Database can be handled through Amazon RDS, this is a native plug as there is nothing specific to Amazon in this case. MongoDB Atlas is also an option for a hosted MongoDB cluster.
- An Amazon S3 bucket can be used for replicated file storage. Our BinaryManager is pluggable and we use it to leverage the S3 Storage capabilities.
The same idea is true for all the cloud specific services like provisioning and monitoring. We try to provide everything so that the deployment in the target IaaS is easy and painless:
- Nuxeo is packaged (among other options) as Debian packages or a docker image
- We can easily setup Nuxeo on top of Amazon Machine Images
- We can use CloudFormation and we provide a template for it
- Nuxeo exposes its metrics via JMX
- CloudWatch can monitor Nuxeo
- We can use autoscaling
Compacting Deployment
Compact Deployment With High Availability
A frequently asked question is whether some applications can be merged on the same machine or not. The answer is yes! We will show such an option here and explain the design choices.
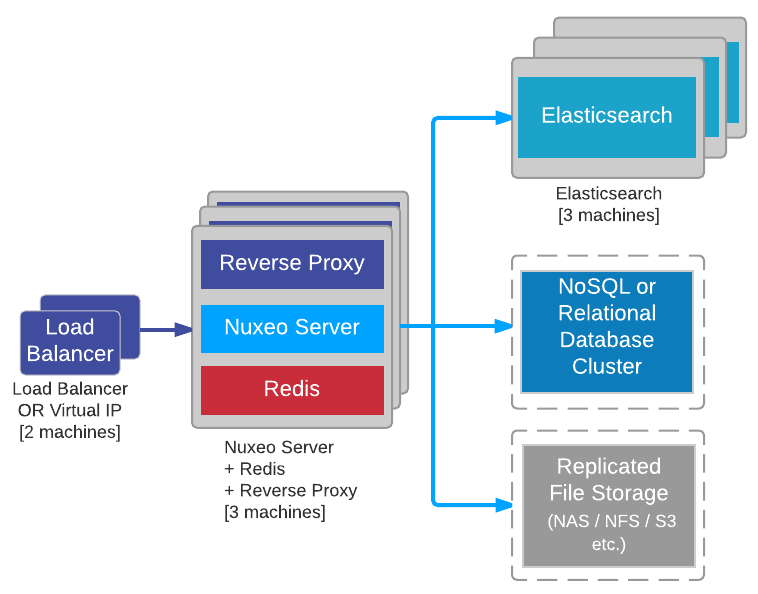
We see here how applications can be merged.
- The load balancers are usually deployed on separate machines from where the Nuxeo server nodes will be, as otherwise stopping a Nuxeo node could have consequences on serving the requests.
- On the machines where Nuxeo server nodes will be installed, a reverse proxy can be installed as well. It is lightweight, and having a reverse proxy for each Nuxeo node makes sense: if it fails for some reason, only the Nuxeo node behind it will be affected.
- Redis, if used, can be installed on the same machine as Nuxeo server: our Redis usage is usually low enough for that.
- Elasticsearch nodes have to be installed on dedicated machines for performance reasons. Elasticsearch uses half of the machine's memory for its heap and half for the system, and is not designed to share memory with another application using the JVM.
- Kafka cluster is better on dedicated machines for isolation purpose.
Compact Deployment With Limited Failover
Providing transparent upgrades without service interruption using a very limited number of machines is also possible, at the cost of some limitations. The following architecture example demonstrates this option.
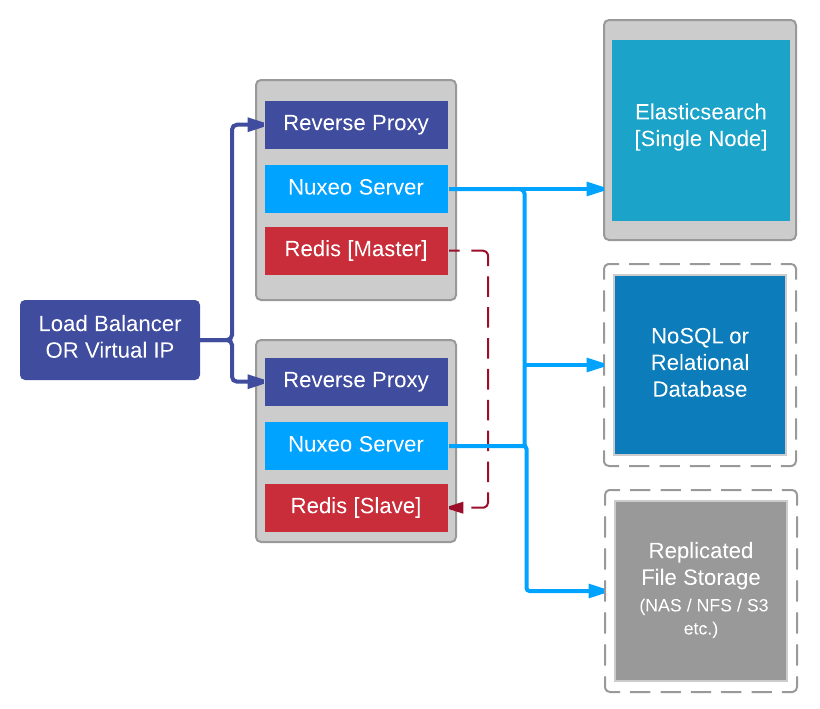
In this architecture:
- A load balancer with sticky sessions is used.
- A total of two machines are prepared for the application cluster. Each machine holds a Nuxeo server node, a Redis node, and a reverse proxy. More machines can be added later for scalability purpose.
- Since we have two Redis nodes, we take advantage from it to configure Redis in master / slave mode.
- A single Elasticsearch node is used.
- A single Kafka node is used.
Limitations
Potential Single Point of Failures
Two potential single points of failure exist in this architecture: the Elasticsearch server and the database server.
Database Server
The database server is the most impacting of the two; if it fails, you won't able to store or retrieve documents anymore. To prevent the database server from becoming a single point of failure, you have several options:
- Use database replication
- Use a clusterized database (like Oracle RAC)
- Use a distributed / failsafe database like MongoDB
Elasticsearch Server
Some features won't be available in your application during an Elasticsearch downtime: search screens and views that depend on the Elasticsearch index mainly. But even in a hard failure situation leading to complete data loss, it will not be that impacting as long as you configure your Nuxeo Server to store audit and sequences in the database: after reinstalling Elasticsearch the document index can be rebuilt easily using Nuxeo Server.
Redis in Master / Slave Mode
Redis server is known to be very resilient, and is less impacting when failing; this is why we considered deploying it in master / slave mode in our architecture schema. If it ever fails, consequences will be rather low as it mainly stores transient data, but you would still lose pending asynchronous jobs in the process. Losing these jobs will result in a loss of features in the application, but will not prevent it from working overall.
Depending on the importance of these jobs in your application (for instance they could be considered mission critical in a DAM application), you have options to provide high availability using Redis. You can refer to our Nuxeo architecture introduction page for details. Remember that if choosing sentinel you will need at least 3 Redis nodes to prevent the split-brain problem.