This page describes how your Nuxeo cluster can scale depending on your needs.
Scaling out Processing
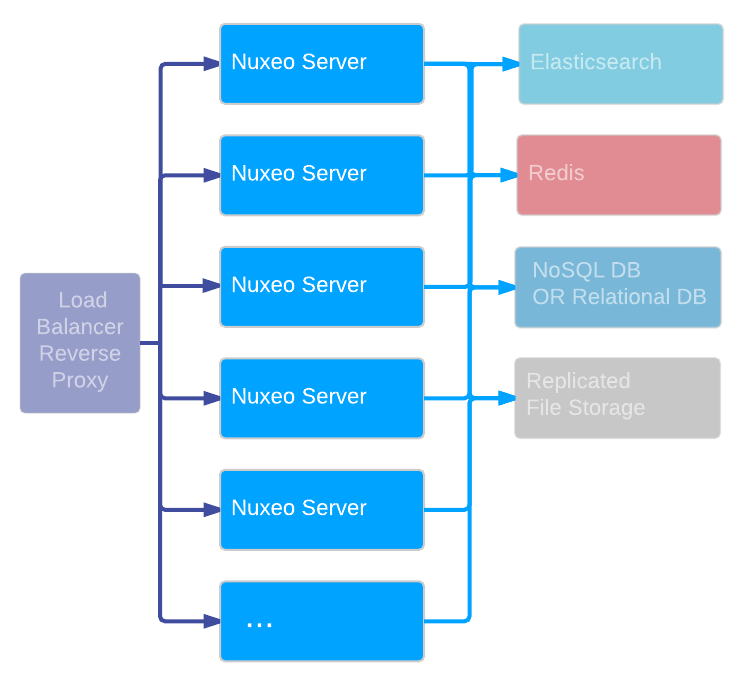
Nuxeo Server by itself allows you to scale out processing: you can add new nodes as the number of requests increase.
Dedicated Processing Nodes
Applications requiring heavy processing like picture or video conversions can take benefit from having some Nuxeo Server nodes dedicated to these asynchronous tasks. Having such a demarcation between nodes is a good way to be sure that async processing won't slow down interactive processing.
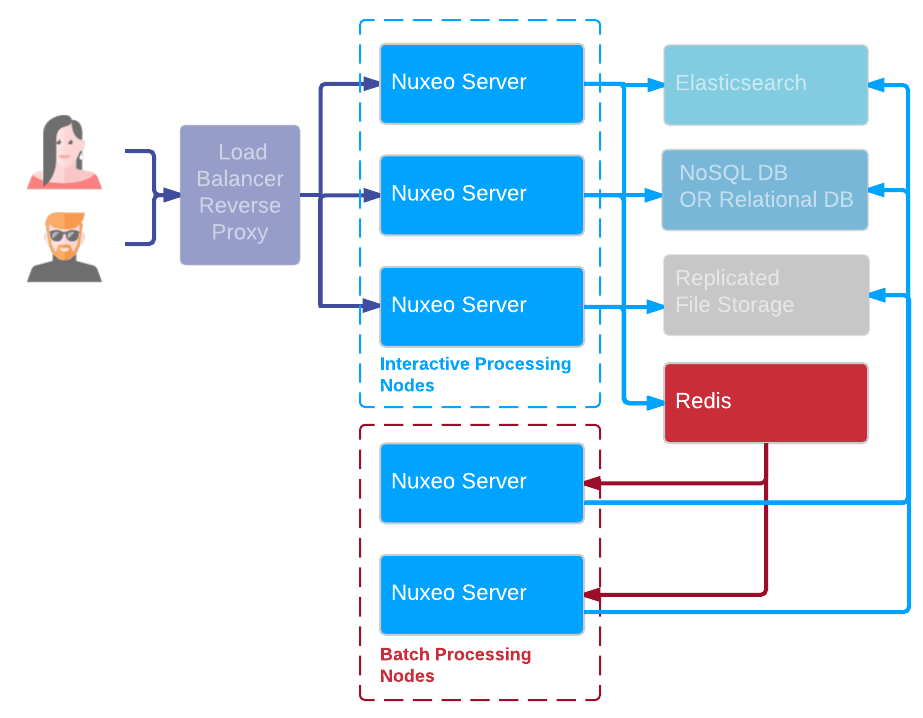
The async tasks can be managed in a distributed way using the WorkManager and Redis.
Scaling the Queries
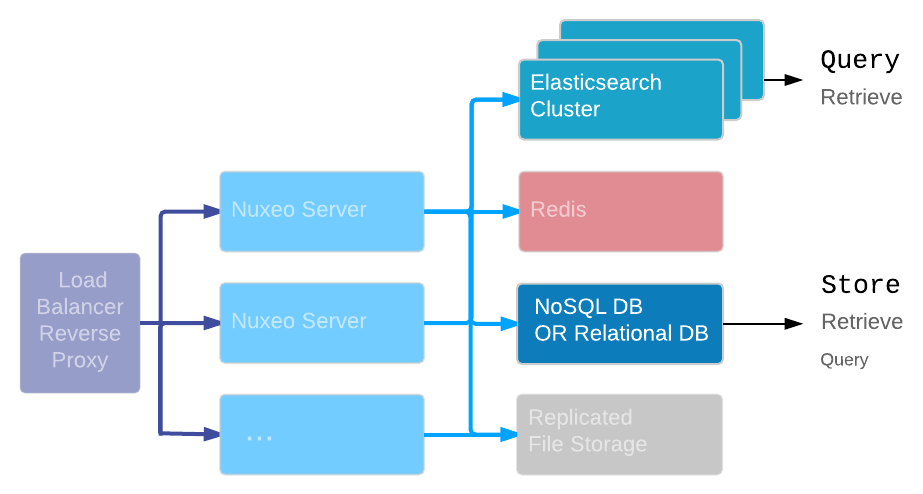
When correctly configured, most databases can handle a heavy load of store and retrieve operations: the first bottleneck is usually complex queries.
So, a first solution to scale out the storage layer is to split the work between:
- The database
- Focus on Store & Retrieve operations
- Small technical queries
- Elasticsearch index
- Handle complex search used to build the screens
- Can also be used to retrieve the document that is fully stored in the index.
At the Nuxeo level, directing a query to the repository database or to Elasticsearch is just a matter of configuration: code and query remain the same. You can refer to the moving load from database to Elasticsearch page for details.
This approach allows you to leverage Elasticsearch capabilities to its fullest:
- Very fast query engine with advanced querying options
- Capability to scale out easily
Scaling out Storage
As seen before, it is easy to scale out processing on Nuxeo Platform, you only need to add more Nuxeo Server nodes. However, at some point, you may also need to be able to scale out the storage layer: we provide several options for that.
Scaling File Storage
Nuxeo natively deduplicates files attached to your documents, which makes the necessary disk space to operate your applications lower. Still, there are a few details you might wish to know.
When storing files in the cloud using for instance the native Amazon S3 connector we provide, you don't need to worry about how files will be distributed on the filesystem.
When storing files on premise, Nuxeo arranges to maximize performances by distributing files in subfolders. A md5 checksum of the file is calculated, and the file is stored in a two-level folder structure named after the first characters of the checksum.
For example, a file having the following checksum: 38c8a503c45169a0668c4ef0c2dc12ec would be stored in a 38/c8 folder structure. The number of characters used for the folder naming is easily configurable, although it's unlikely you will need more than the two characters used by default:
- Each folder level is made of 256 combinations (16 * 16 characters),
- That means we reach a total of 65536 folder combinations in total (16^4),
- If we store 1000 files per folder, we are over 65 million files stored (65 536 000).
Even older filesystems have no performance problem until 10 000 files per folder, which gives you a lot of latitude. Past a certain point, you may wish however to lower costs by distributing files between different hardware solutions. This can easily be achieved by adding repositories in your application, and we describe this solution in the scaling database storage below.
Scaling Database Storage
NoSQL Databases
One of the key advantages of NoSQL databases, like MongoDB, is that they allow to scale out by simply adding nodes to the cluster and natively offer sharding on the nodes.
Relational Databases
Unlike NoSQL databases, relational database nodes can't simply be added to handle more load:
- Multi-masters SQL DB architecture (like Oracle RAC) work but don't really provide scale out, only HA.
- Leveraging replicated ReadOnly SQL DB nodes is complex in terms of transaction management
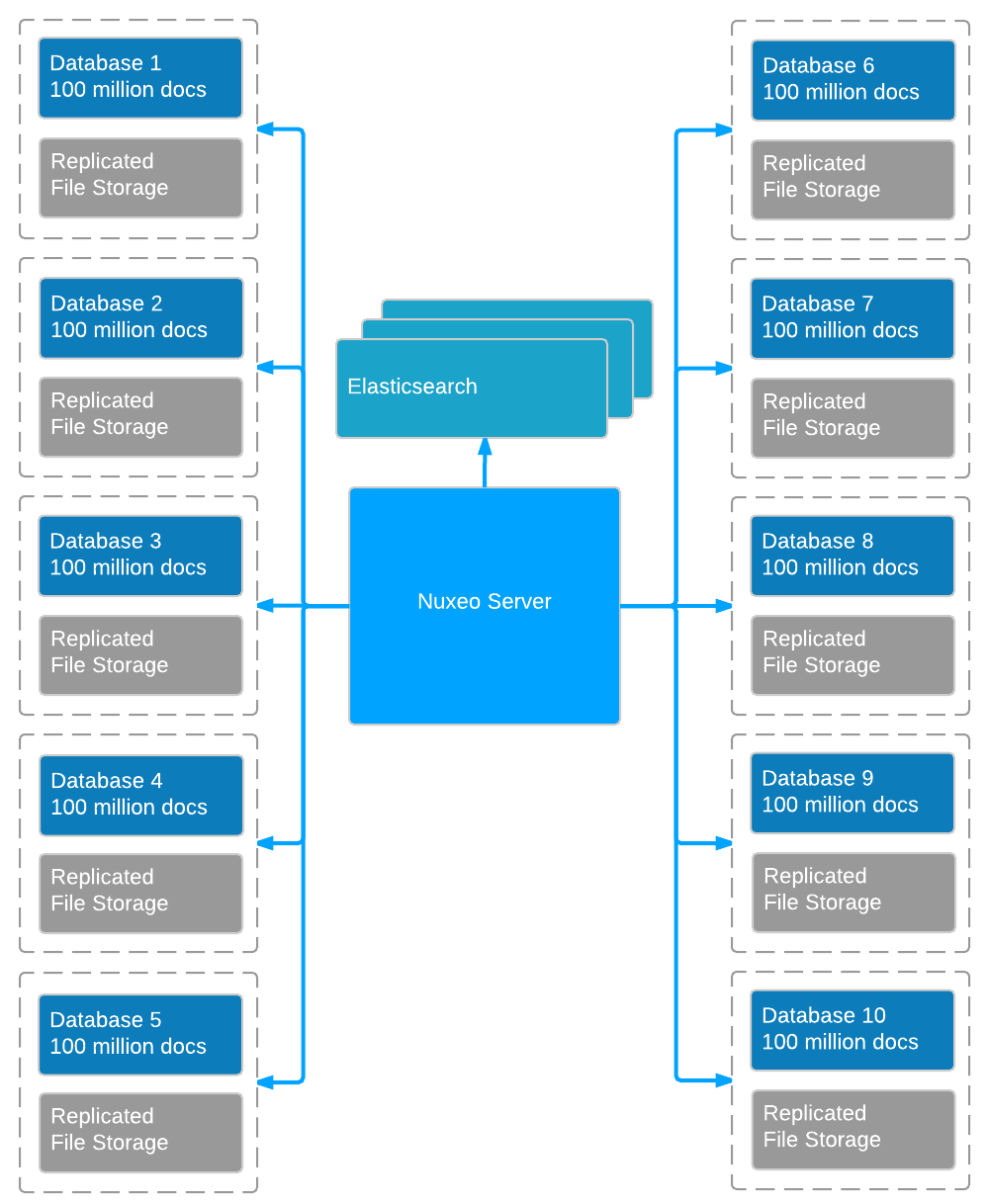
However, the Nuxeo Platform does provide a way to scale out the data: using several repositories. The idea is that a single Nuxeo application can be bound to several repositories, each repository being a database instance and a file storage solution. So if one application is connected to two repositories, the data will be partitioned between two couples (ex: (DB+FS) + (DB+S3)).
The repositories are like mount points: The default configuration is to have only one repository named "Default Repository" and mounted under /default/. But you can add new repositories as needed. These new repositories will appear inside the application as several content roots. This typically means that when accessing a document, you have to know what the host repository is.
Typical use cases for data partitioning include:
Selecting your storage type according to the needs
- Partitioning between live and archived documents:
- Archive
- Storage: slower but massive cheap storage that can scale
- Indexes: add indexes on the database to make search faster (few writes)
- Live
- Storage: fast storage to make work faster, lower volume
- Indexes: fast database with few indexes to maximize write speed
- Archive
- Partitioning between read-only and read-write repositories
- Have a read-write repository
- Have a read-only replicated repository
Selecting the storage according to the isolation policy
- Data for "clientX" goes in "repositoryX"
- Partitioning between types of documents or document status:
- Published documents in a public repository
- Working documents in a restricted repository
This data partitioning is visible to end users, but thanks to Elasticsearch we can provide a unified index. It means searches can be executed in all repositories seamlessly, and any document query or listing can take advantage of this unified index too when necessary.
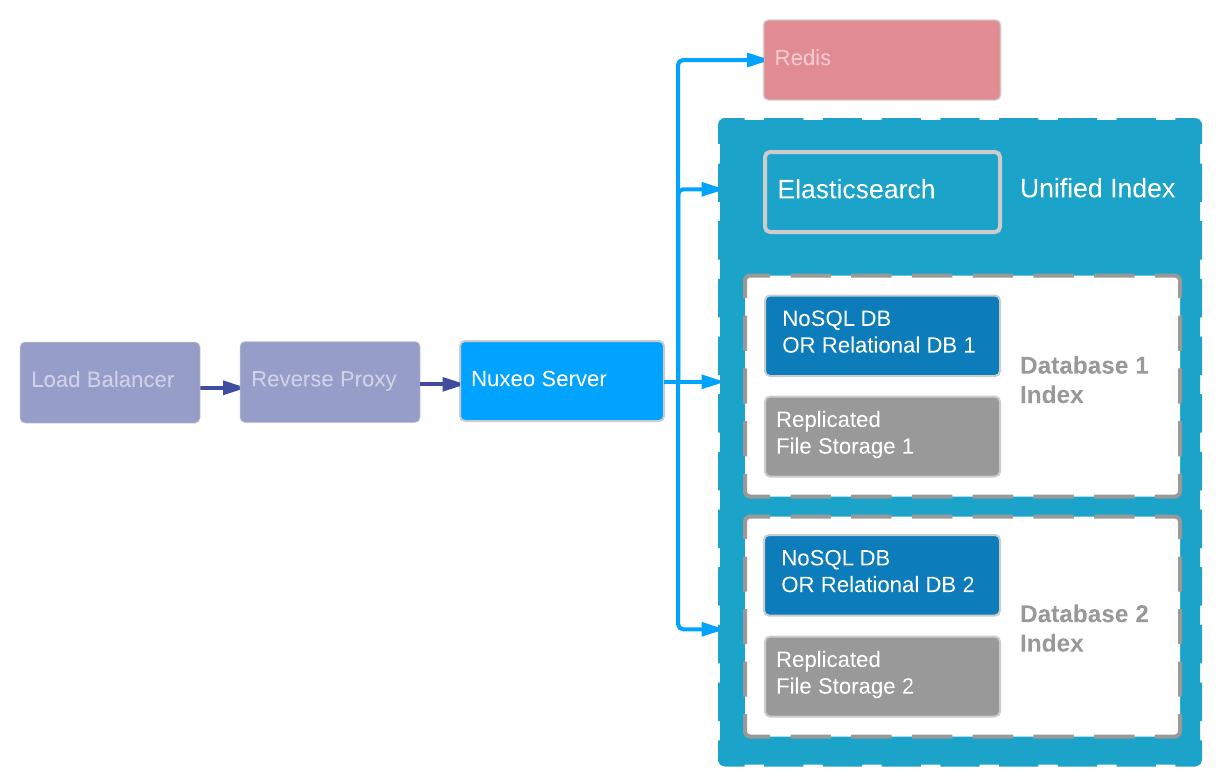
This type of sharding has been tested during a performance benchmark using 10 PostgreSQL databases to reach a total of 1 billion documents.