Fragment Tables
Some databases may use a database-native UUID instead of a string-based UUID if Nuxeo is configured to do so, or even an automatically-generated small integer instead (see nuxeo.vcs.idtype in Configuration Parameters Index (nuxeo.conf) or <idType> in Repository Configuration).
All the fragments making up a given node use the node id in their id column.
For clarity in the rest of this document simple integers are used, but Nuxeo actually uses UUIDs, like 56e42c3f-db99-4b18-83ec-601e0653f906 for example.
Hierarchy Table
There are two kinds of nodes: filed ones (those who have a location in the containment hierarchy), and unfiled ones (version frozen nodes, and some other documents like tags).
Each node has a row in the main hierarchy table defining its containment information if it is filed, or just holding its name if it is unfiled. The same tables holds ordering information for ordered children.
Table hierarchy:
| id | parentid | pos | name | ... |
|---|---|---|---|---|
| 1 | "" | |||
| 1234 | 1 | workspace | ||
| 5678 | 1234 | mydoc |
Note that:
- The
idcolumn is used as aFOREIGN KEYreference withON DELETE CASCADEfrom all other fragment tables that refer to it, - The
posisNULLfor non-ordered children, - The
parentidandposareNULLfor unfiled nodes, - The
nameis an empty string for the hierarchy's root.
For performance reasons (denormalization) this table has actually more columns; they are detailed below.
Type Information
The node types are accessed from the main hierarchy table.
When retrieving a node by its id the primarytype and mixintypes are consulted. According to their values a set of applicable fragments is deduced, to give a full information of all the fragment tables that apply to this node.
Table hierarchy (continued):
| id | ... | isproperty | primarytype | mixintypes | ... |
|---|---|---|---|---|---|
| 1 | FALSE | Root | |||
| 1234 | FALSE | Bar | |||
| 5678 | FALSE | MyType | [Facet1,Facet2] |
The isproperty column holds a boolean that distinguishes normal children from complex properties,
The mixintypes stores a set of mixins (called Facets in the high-level documentation). For databases that support arrays (PostgreSQL), they are stored as an array; for other databases, they are stored as a |-separated string with initial and final | terminators (in order to allow efficient LIKE-based matching) — for the example row 5678 above the mixins would be stored as the string |Facet1|Facet2|.
Simple Fragment Tables
Each Nuxeo schema corresponds to one table. The table's columns are all the single-valued properties of the corresponding schema. Multi-valued properties are stored in a separate table each.
A "myschema" fragment (corresponding to a Nuxeo schema with the same name) will have the following table:
Table myschema:
| id | title | description | created |
|---|---|---|---|
| 5678 | Mickey | The Mouse | 2008-08-01 12:56:15.000 |
A consequence is that to retrieve the content of a node, a SELECT will have to be done in each of the tables corresponding to the node type and all its inherited node types. However lazy retrieval of a node's content means that in many cases only a subset of these tables will be needed.
Collection Fragment Tables
A multi-valued property is represented as data from a separate array table holding the values and their order. For instance, the property "my:subjects" of the schema "myschema" with prefix "my" will be stored in the following table:
Table my_subjects:
| id | pos | item |
|---|---|---|
| 5678 | 0 | USA |
| 5678 | 1 | CTU |
Files and Blobs
The blob abstraction in Nuxeo is treated by the storage as any other schema, "content", except that one of the columns, data, hold a blob key. This blob key corresponds indirectly to the content of the file. Because the content schema is used as a complex property, there are two entries in the hierarchy table for each document.
Table hierarchy:
| id | parentid | name | isproperty | primarytype | ... |
|---|---|---|---|---|---|
| 4061 | 5678 | myreport | FALSE | File | |
| 4062 | 5678 | test | FALSE | File | |
| 4063 | 5678 | test2 | FALSE | File | |
| 8501 | 4061 | content | TRUE | content | |
| 8502 | 4062 | content | TRUE | content | |
| 8503 | 4063 | content | TRUE | content |
Table content:
| id | data | name | mime-type | encoding | length | digest |
|---|---|---|---|---|---|---|
| 8501 | ebca0d868ef3 | report.pdf | application/pdf | 344256 | ||
| 8502 | 5f3b55a834a0 | test.txt | text/plain | ISO-8859-1 | 541 | |
| 8503 | 5f3b55a834a0 | test_copy.txt | text/plain | ISO-8859-1 | 541 |
Table file:
| id | filename |
|---|---|
| 4061 | report.pdf |
| 4062 | test.txt |
| 4063 | test_copy.txt |
The filename of a blob is primarily stored in the name column of the content table. For historical reasons, the filename is also stored in a separate file table.
The data column of the content table refers to a blob key. All blob storage is done through the BlobManager interface of Nuxeo though various BlobProviders. There is usually only one blob provider configured for a repository, in which case the blob key will be directly a value that can be consumed by the blob provider. But if, due to the presence of a BlobDispatcher, several blob providers may be used for a single repository, then the blob key will be prefixed by the blob provider name, for instance s3:6f45afa854b2c0d8cd047fd7a86b1378 for an "s3" blob provider.
The default blob provider implementation stores binaries on the server filesystem according to the value stored in the data column, which is computed as a cryptographic hash of the binary in order to check for uniqueness and share identical binaries (hashes are actually longer than shown here). On the server filesystem, a binary is stored in a set of multi-level directories based on the has, to spread storage. For instance the binary with the hash c38fcf32f16e4fea074c21abb4c5fd07 will be stored in a file with path data/c3/8f/c38fcf32f16e4fea074c21abb4c5fd07 under the binaries root.
Other blob providers use the data column differently to refer to their blobs, for instance the FilesystemBlobProvider uses a relative path to a file in a special area of the filesystem. The GoogleDriveBlobProvider uses the concatenation of a user email and a Google Drive file id with an optional revision number.
Relations
Nuxeo relations are stored using VCS.
Table relation:
| id | source | sourceUri | target | targetUri | targetString |
|---|---|---|---|---|---|
| 1843 | 5670 | 5700 | |||
| 1844 | 5670 | "some text" |
The source and target columns hold document ids (keyed by the hierarchy table). The relation object itself is a document, so its id is present in the hierarchy table as well, with the primarytype "Relation" or a subtype of it.
In the case of tags, the relation document has type "Tagging", its source is the document being tagged, and its target has type "Tag" (a type with a schema "tag" that contains a field "label" which is the actual tag).
Versioning
You may want to read background information about Nuxeo versioning first.
Versioning uses identifiers for several concepts:
- Live node id: the identifier of a node that may be subject to versioning.
- Version id: the identifier of the frozen node copy that is created when a version was snapshotted, often just called a "version".
- Versionable id or version series id: the identifier of the original live node of a version, but which keeps its meaning even after the live node may be deleted. Several frozen version nodes may come from the same live node, and therefore have the same versionable id, which is why it is also called also the version series id.
Version nodes don't have a parent (they are unfiled), but have more meta-information (versionable id, various information) than live nodes. Live nodes hold information about the version they are derived from (base version id).
Table hierarchy (continued):
| id | ... | isversion | ischeckedin | baseversionid | majorversion | minorversion |
|---|---|---|---|---|---|---|
| 5675 | TRUE | 6120 | 1 | 0 | ||
| 5678 | FALSE | 6143 | 1 | 1 | ||
| 5710 | FALSE | |||||
| 6120 | TRUE | 1 | 0 | |||
| 6121 | TRUE | 1 | 1 | |||
| 6143 | TRUE | 4 | 3 |
Note that:
- This information is inlined in the hierarchy table for performance reasons,
- The
baseversionidrepresents the version from which a checked out or checked in document originates. For a new document that has never been checked in it isNULL.
Table versions:
| id | versionableid | created | label | description | islatest | islatestmajor |
|---|---|---|---|---|---|---|
| 6120 | 5675 | 2007-02-27 12:30:00.000 | 1.0 | FALSE | TRUE | |
| 6121 | 5675 | 2007-02-28 03:45:05.000 | 1.1 | TRUE | FALSE | |
| 6143 | 5678 | 2008-01-15 08:13:47.000 | 4.3 | TRUE | FALSE |
Note that:
- The
versionableidis the id of the versionable node (which may not exist anymore, which means it's not aFOREIGN KEYreference), and is common to a set of versions for the same node, it is used as a version series id. islatestis true for the last version created,islatestmajoris true for the last major version created, a major version being a version whose minor version number is 0,- The
labelcontains a concatenation of the major and minor version numbers for users' benefit.
Proxies
Proxies are a Nuxeo feature, expressed as a node type holding only a reference to a frozen node and a convenience reference to the versionable node of that frozen node.
Proxies by themselves don't have additional content-related schema, but still have security, locking, etc. These facts are part of the node type inheritance, but the proxy node type table by itself is a normal node type table.
Table proxies:
| id | targetid | versionableid |
|---|---|---|
| 9944 | 6120 | 5675 |
Note that:
targetidis the id of a version node and is aFOREIGN KEYreference tohierarchy.id.versionableidis duplicated here for performance reasons, although it could be retrieved from the target using aJOIN.
Locking
When configured (this is the default) to be stored in the VCS database, the locks are held in a table containing the lock owner and a timestamp of the lock creation time.
Table locks:
| id | owner | created |
|---|---|---|
| 5670 | Administrator | 2008-08-20 12:30:00.000 |
| 5678 | cobrian | 2008-08-20 12:30:05.000 |
| 9944 | jbauer | 2008-08-21 14:21:13.488 |
When a document is unlocked, the corresponding line is deleted.
Another important feature of the locks table is that the id column is not a foreign key to hierarchy.id. This is necessary in order to isolate the locking subsystem from writing transactions on the main data, to have atomic locks. It is also necessary to be able to lock a document before it is first created in the database.
Security
The Nuxeo security model is based on the following:
- A single ACP is placed on a (document) node,
- The ACP contains an ordered list of named ACLs, each ACL being an ordered list of individual grants or denies of permissions,
- The security information on a node (materialized by the ACP) also contains local group information (which can emulate owners).
Table acls:
| id | pos | name | grant | permission | user | group |
|---|---|---|---|---|---|---|
| 5678 | 0 | local | true | WriteProperties | cobrian | |
| 5678 | 1 | local | false | ReadProperties | Reviewer | |
| 5678 | 2 | workflow | false | ReadProperties | kbauer |
This table is slightly denormalized (names with identical values follow each other by pos ordering), but this is to minimize the number of JOINs to get all ACLs for a document. Also one cannot have a named ACL with an empty list of ACEs in it, but this is not a problem given the semantics of ACLs.
The user column is separated from the group column because they semantically belong to different namespaces. However for now in Nuxeo groups and users are all mixed in the user column, and the group column is unused.
Miscellaneous Values
The lifecycle information (life ycle policy and lifecycle state) is stored in a dedicated table.
Table misc:
| id | lifecyclepolicy | lifecyclestate |
|---|---|---|
| 5670 | default | draft |
| 5678 | default | current |
| 9944 | publishing | pending |
Full-text
The full-text indexing table holds information about the fulltext extracted from a document, and is used when fulltext queries are made. The structure of this table depends a lot on the underlying SQL database used, because each database has its own way of doing fulltext indexing. The basic structure is as follow:
Table fulltext:
| id | jobid | fulltext | simpletext | binarytext |
|---|---|---|---|---|
| 5678 | 5678 | Mickey Mouse USA CTU report pdf reporttitle ... | Mickey Mouse USA CTU report pdf | reporttitle ... |
The simpletext column holds text extracted from the string properties of the document configured for indexing. The binarytext column holds text extracted from the blob properties of the document configured for indexing. The fulltext column is the concatenation of the two and is the one usually indexed as fulltext by the database. A database trigger updates fulltext as soon as simpletext or binarytext is changed.
The jobid column holds the document identifier of the document being indexed. Once the asynchronous job complete, all the rows that have a jobid matching the document id are filled with the computed full-text information. This ensures in most cases that the fulltext information is well propagated to all copies of the documents.
Some databases can directly index several columns at a time, in which case the fulltext column doesn't exist, there is no trigger, and the two simpletext and binarytext columns are indexed together.
The above three columns show the data stored and indexed for the default fulltext index, but Nuxeo allows any number of additional indexes to be used (indexing a separate set of properties). In this case additional columns are present, suffixed by the index name; for instance for index "main" you would find the additional columns:
Table fulltext (continued):
| id | ... | fulltext_main | simpletext_main | binarytext_main |
|---|---|---|---|---|
| 5678 | bla | bla |
Other System Tables
Repositories
This table hold the root id for each repository. Usually Nuxeo has only one repository per database, which is named "default".
Table repositories:
| id | name |
|---|---|
| 1 | default |
Note that the id column is a FOREIGN KEY to hierarchy.id.
Clustering
When configured for cluster mode, two additional tables are used to store cluster node information and cluster invalidations.
A new row is created automatically in the cluster nodes table when a new cluster node connects to the database. It is automatically removed when the cluster node shuts down.
Table cluster_nodes:
| nodeid | created |
|---|---|
| 71 | 2008-08-01 12:31:04.580 |
| 78 | 2008-08-01 12:34:51.663 |
| 83 | 2008-08-01 12:35:27.184 |
Note that:
- The
nodeidis assigned by Nuxeo from the configuredrepository.clustering.id. - The
createddate is not used by Nuxeo but is useful for diagnostics.
The cluster invalidations are inserted when a transaction commits, the invalidation rows are duplicated for all cluster node ids that are not the current cluster node. Rows are removed as soon as a cluster node checks for its own invalidations, usually at the beginning of a transaction.
Table cluster_invals:
| nodeid | id | fragments | kind |
|---|---|---|---|
| 78 | 5670 | hierarchy, dublincore, misc | 1 |
| 78 | 5678 | dublincore | 1 |
| 83 | 5670 | hierarchy, dublincore, misc | 1 |
| 83 | 5678 | dublincore | 1 |
Note that:
nodeidis a node id but is not aFOREIGN KEYtohierarchy.idfor speed reasons.fragmentsis the list of fragments to invalidate; it is a space-separated string, or an array of strings for databases that support arrays.kindis 1 for modification invalidations, or 2 for deletion invalidations.
Path Optimizations
For databases that support it, some path optimizations allow faster computation of the NXQL STARTSWITH operator and ecm:ancestorId property.
When path optimizations are enabled (this is the default on supported databases), an addition table stores the descendants of every document. This table is updated through triggers when documents are added, deleted or moved.
Table descendants:
| id | descendantid |
|---|---|
| 1 | 1234 |
| 1 | 5678 |
| 1234 | 5678 |
Note that descendantid is a FOREIGN KEY to hierarchy.id.
Another more efficient optimization is used instead for PostgreSQL (see NXP-5390). For this optimization, an ancestors table stores all the ancestors as an array in a single cell. This table is also updated through triggers:
Table ancestors:
| id | ancestors |
|---|---|
| 1234 | [1] |
| 5678 | [1, 1234] |
The ancestors column contains the array of ordered ancestors of each document (not complex properties), with the root at the beginning of the array and the direct parent at the end.
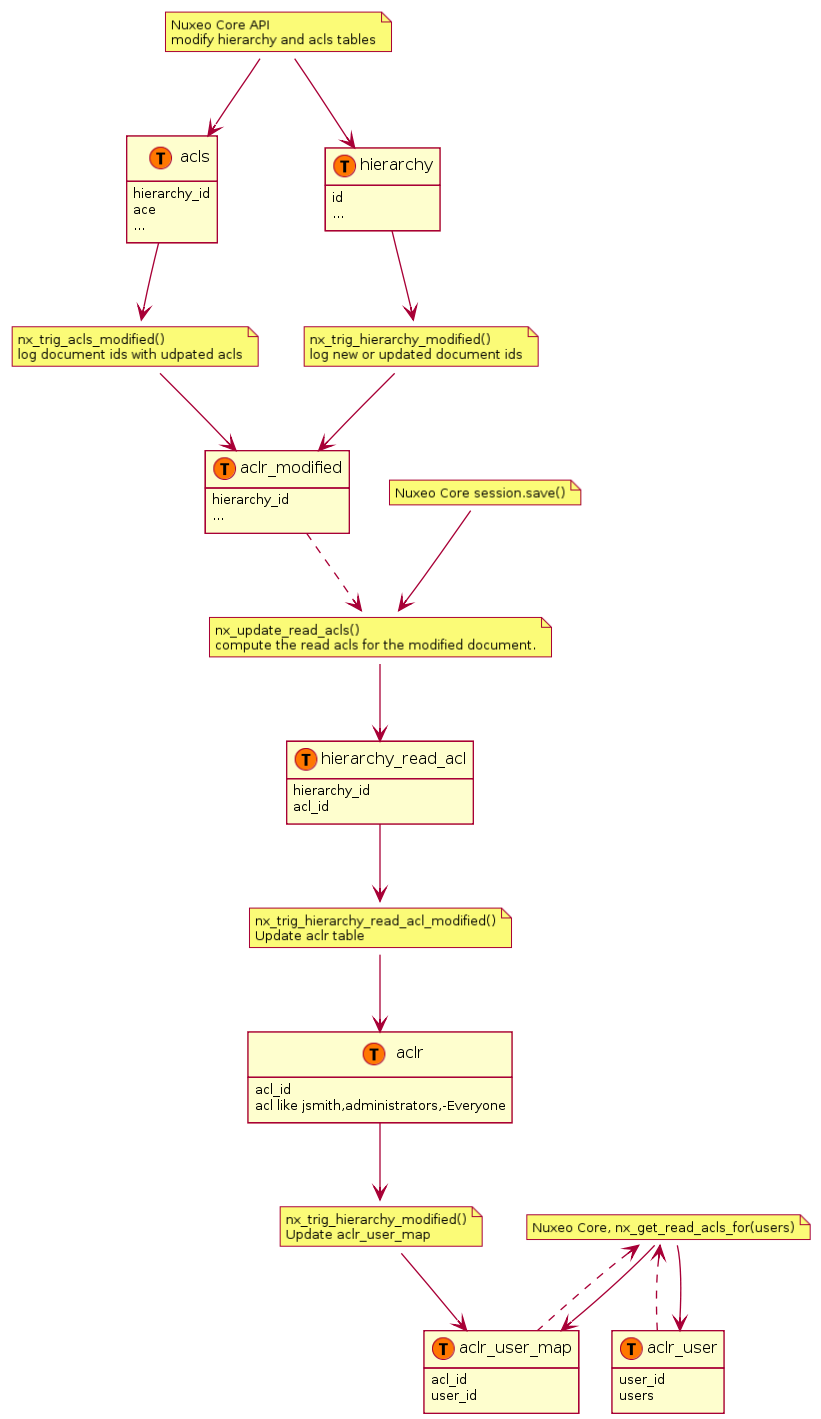
ACL Optimizations
For databases that support it, ACL optimizations allow faster security checks than the NX_ACCESS_ALLOWED stored procedure used in standard.
The hierarchy_read_acl table stores information about the complete ACL that applies to a document.
Table hierarchy_read_acl:
| id | acl_id |
|---|---|
| 5678 | bc61ba9c8dbf034468ac361ae068912b |
The acl_id is the unique identifier for the complete read ACL (merged with ancestors) for this document. It references the id column in the read_acls table, but not using a FOREIGN KEY for speed reasons.
The read_acls table stores all the possibles ACLs and their unique id.
Table aclr:
| acl_id | acl |
|---|---|
| bc61ba9c8dbf034468ac361ae068912b | -Reviewer,-kbauer,Administrator,administrators |
The unique ACL id is computed through a hash to simplify unicity checks.
When a security check has to be done, the user and all its groups are passed to a stored procedure (usually NX_GET_READ_ACLS_FOR), and the resulting values are JOINed to the hierarchy_read_acl table to limit document ids to match.
The NX_GET_READ_ACLS_FOR stored procedure has to find all ACLs for a given user, and the results of that can be cached in the read_acls_cache table. This cache is invalidated as soon as security on a document changes.
Table aclr_user_map:
| users_id | acl_id |
|---|---|
| f4bb42d8 | 1 |
| f4bb42d8 | 1234 |
| f4bb42d8 | 5678 |
| c5ad3c99 | 1 |
| c5ad3c99 | 1234 |
Table aclr_user:
| user_id | users |
|---|---|
| f4bb42d8 | Administrator,administrators |
| c5ad3c99 | kbauer,members |
Note:
f4bb42d8is the MD5 hash for "Administrator,administrators",c5ad3c99is the MD5 hash for "kbauer,members".- A hash is used to make sure this column has a limited size.
An additional table, aclr_modified, is used to temporarily log document ids where ACLs are modified.
Table aclr_modified:
| hierarchy_id | is_new |
|---|---|
| 5678 | false |
| 5690 | true |
Note that:
hierarchy_idis a reference tohierarchy.idbut does not use aFOREIGN KEYfor speed reasons.is_newis false (or 0) for an ACL modification (which has impact on the document's children), and true (or 1) for a new document creation (where the merged ACL has to be computed).
This table is filled while a set of ACL modifications are in progress, and when the Nuxeo session is saved the stored procedure NX_UPDATE_READ_ACLS is called to recompute what's needed according to hierarchy_modified_acl, which is then emptied.
To be more efficient in read/write concurrency, when a new ACL is added the list of read ACL per user is updated instead of being flushed. This is done using database triggers. Note that some tables have been renamed and prefixed by aclr_ (for ACL Read). Following is a big picture of the trigger processing: