The Bulk Action Framework provides a service to be able to run resilient bulk actions on a possibly large set of documents.
This framework introduces several notions:
- document set: a list of documents from a repository represented as a list of document identifiers.
- action: an operation that can be applied to a document set.
- command: a set of parameters building a request to apply an action on a document set.
- bucket: a portion of a document set that fits into a stream record.
- batch: a smaller (or equals) portion of a bucket where the action is applied within a transaction.
RequirementsTo work properly, the Bulk Service needs a true KeyValue storage to store the command and its status: the
MongoDBKeyValueStoreif you are using the MongoDB template or theSQLKeyValueStoreotherwise. You should not rely on the defaultMemKeyValueStoreimplementation that flushes the data on restart.
Bulk Service
This service provides ways to:
- Submit a command to be executed.
- Get the status of a submitted command.
- Get the result of a submitted command.
- Abort a submitted command.
- Wait for a command to be completely executed.
- Wait for all running commands to be completely executed (for tests).
The following is an example of bulk service usage:
// build command
BulkCommand command = new BulkCommand.Builder(SetPropertiesAction.ACTION_NAME,
"SELECT * from Document").repository("default")
.user("Administrator")
.param("dc:nature", "article")
.param("dc:subjects", Collections.singletonList("art/architecture"))
// default is FALSE
.param(SetPropertiesAction.PARAM_DISABLE_AUDIT, Boolean.TRUE)
// default is null - only NONE can be set
.param(SetPropertiesAction.PARAM_VERSIONING_OPTION, "NONE")
.build();
// run command
BulkService bulkService = Framework.getService(BulkService.class);
String commandId = bulkService.submit(command);
// await end of computation
bulkService.await(commandId, Duration.ofMinutes(1));
// get status
BulkStatus status = bulkService.getStatus(commandId);
Execution Flow
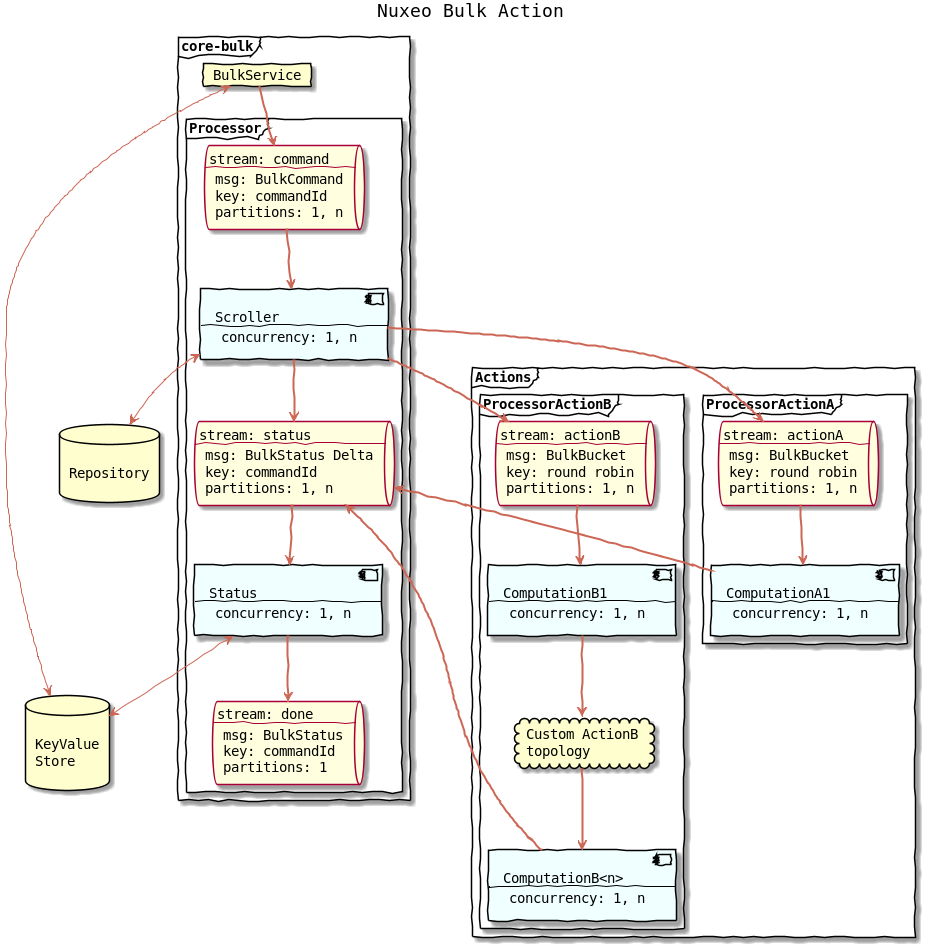
BulkService
The entry point is the BulkService that takes a bulk command as an input. The service submits this command, meaning it appends the BulkCommand to the command stream.
The BulkService can also return the status of a command which is internally stored into a KeyValueStore.
Scroller Computation
The command stream is the input of the Scroller computation.
This computation scrolls the database using a cursor to retrieve the document ids matching the NXQL query. The ids are grouped into a bucket that fit into a record.
The BulkBucket record is appended to the action's stream.
The scroller sends command status update to inform that the scroll is in progress or terminated and to set the total number of document in the materialized document set.
Actions Processors
Each action runs its own stream processor (a topology of computations).
The action processor must respect the following rules:
- action must send a status update containing the number of processed documents since the last update.
- action must handle possible error, for instance the user that send the command might not have write permission on all documents
- the total number of processed documents reported must match at some point the number of documents in the document set.
- action that aggregates bucket records per command must handle interleaved commands. This can be done by maintaining a local state for each command.
- action that aggregates bucket records per command should checkpoint only when there no other interleaved command in progress. This is to prevent checkpoint while some records are not yet processed resulting in possible loss of record.
An AbstractBulkComputation is provided so an action can be implemented easily with a single computation. See SetPropertiesAction for a simple example.
See The CSVExportAction and particularly the MakeBlob computation for an advanced example.
Status Computation
This computation reads from the status stream and aggregate status update to build the current status of command. The status is saved into a KeyValueStore. When the number of processed document is equals to the number of document in the set, the state is changed to completed. And the computation appends the final status to the done stream.
This done stream can be used as an input by custom computation to execute other actions once a command is completed.
Contributing an Action
You need to register a couple action/stream processor:
<extension target="org.nuxeo.ecm.core.bulk" point="actions">
<action name="myAction" bucketSize="100" batchSize="20"/>
</extension>
<extension target="org.nuxeo.runtime.stream.service" point="streamProcessor">
<streamProcessor name="myAction" class="org.nuxeo.ecm.core.bulk.actions.MyActionProcessor" logConfig="bulk"
defaultConcurrency="2" defaultPartitions="4">
</streamProcessor>
</extension>
If your action have some parameters, you can also validate them by adding a validation class to the action contribution:
<action name="myAction" validationClass="org.nuxeo.myValidationClass"/>
It is possible to add several options to the stream processor to tune the way the documents are processed. Please visit nuxeo-runtime-stream README for more information.
Controlling the Bulk Command Execution
A Bulk command submitted to the Bulk Service contains a query that represents a list of items and an action to apply to this set. The execution of the Bulk command is divided into two parts:
- The scroll: The Scroll computation reads the submitted bulk command and materializes the query results into the action stream.
- The processing: The Action computation reads the action stream and applies the action to process the items.
A Bulk action can be flagged as:
- Sequential Scroll: All bulk commands are routed to the same scroll thread, eliminating parallel scrolling. The processing of items in a Bulk command can be concurrent. Multiple Bulk commands may briefly run in parallel, overlapping for a short duration. Example: Actions like delete, update acl, move: where it is better to avoid parallel command that might conflict.
<action name="myAction" sequentialScroll="true" ... /> - Sequential Processing: All items of a Bulk command are processed sequentially by the same action thread. Multiple Bulk commands can be scrolled and processed in parallel. Example: For a Bulk action that run an automation operation to add docs to a collection, with a sequential processing avoids a concurrent update exception.
<action name="myAction" sequentialProcessing="true" ... /> - Exclusive Only one Bulk command can be submitted and run at a time. Submitting a Bulk command while another one is running results in an immediate error. The processing of items in the Bulk command can be concurrent. The entire execution is sequential. Example: heavy administrative operation like: full GC, migration, full reindex, or periodical tasks that can be skipped if already running (transient GC, workflow escalation, ...)
<action name="myAction" exclusive="true" ... />
Note that it is possible to have Sequential Bulk Command by using sequential Scroll with the bulk action on a stream with a single partition, or simply using an exclusive command.
Bulk REST API
Bulk Service APIs are accessible with REST API from two places:
- search endpoint to submit a command
- dedicated bulk endpoint for others actions
Objects transiting between server and client are parameters of bulk action which is a simple JSON object and depend on action needs, and BulkStatus object whose JSON representation is as below:
{
"entity-type": "bulkStatus",
"commandId": "00000000-0000-0000-0000-000000000000",
"state": "COMPLETED",
"action": "myAction",
"username": "myUser",
"total": 127,
"processed": 127,
"error": false,
"errorCount": 0,
"submitted": "2018-06-21T12:37:08.172Z",
"scrollStart": "2018-06-21T12:38:08.172Z",
"scrollEnd": "2018-06-21T12:39:08.172Z",
"processingStart": "2018-06-21T12:39:08.272Z",
"processingEnd": "2018-06-21T12:40:08.072Z",
"processingMillis": 1234,
"completed": "2018-06-21T12:40:08.172Z",
"result": {
"result1": "o1",
"result2": ["o2", "o3"]
}
}
Submit a Command
You can submit a bulk command through REST by using bulk endpoint leveraging the search endpoint. Thus, you can run your command on a query, page provider or saved search.
| Description | HTTP Method | Path | Request Body | Response |
|---|---|---|---|---|
| Submit a bulk command on a NXQL query | POST | /api/v1/search/bulk/{actionId} |
Parameters for bulk action as a JSON object | BulkStatus object |
| Submit a bulk command on a page provider | POST | /api/v1/search/pp/{providerName}/bulk/{actionId} |
Parameters for bulk action as a JSON object | BulkStatus object |
| Submit a bulk command on a saved search | POST | /api/v1/search/saved/{searchId}/bulk/{actionId} |
Parameters for bulk action as a JSON object | BulkStatus object |
For instance:
curl -u Administrator:Administrator \
-H 'Content-Type: application/json' \
-X POST 'http://localhost:8080/nuxeo/api/v1/search/bulk/setProperties?query=SELECT * FROM Document' \
-d '{
"dc:nature": "article",
"dc:subjects": ["art/architecture"],
"disableAuditLogger": true,
"VersioningOption": "NONE"
}'
Handle Your Bulk Execution
Once you have submitted a bulk command, you can use these REST APIs:
| Description | HTTP Method | Path | Request Body | Response |
|---|---|---|---|---|
| Fetch bulk status | GET | /api/v1/bulk/{commandId} |
/ | BulkStatus |
| Abort a bulk execution | PUT | /api/v1/bulk/{commandId}/abort |
/ | BulkStatus |
Bulk Automation Operation
It is possible to submit a command through the Bulk.RunAction automation operation.
The following is an example of use of operation:
curl -u Administrator:Administrator \
-H 'Content-Type: application/json' \
-X POST 'http://localhost:8080/nuxeo/api/v1/automation/Bulk.RunAction' \
-d '{"params":{
"query":"SELECT * FROM Document",
"action":"setProperties",
"parameters":"{\"dc:nature\":\"article\",\"dc:subjects\":[\"art\/architecture\"]}"
}
}'
For testing purpose, it is possible to wait for the end of a bulk action with the Bulk.WaitForAction automation operation.
Testing a Bulk Action with REST API
Here is an example on how to launch a bulk command and get status:
## Run a bulk action
curl -s -X POST 'http://localhost:8080/nuxeo/api/v1/search/bulk/csvExport?query=SELECT%20*%20FROM%20File%20WHERE%20ecm:isVersion=0%20AND%20ecm:isTrashed=0' -u Administrator:Administrator -H ‘content-type: application/json’ -d ‘{}’ | tee /tmp/bulk-command.txt
# {"commandId":"e8cc059d-6b9d-480b-a6e1-b0edace6d982"}
## Extract the command id from the output
commandId=$(cat /tmp/bulk-command.txt | jq .[] | tr -d '"')
## Ask for the command status
curl -s -X GET "http://localhost:8080/nuxeo/api/v1/bulk/$commandId" -u Administrator:Administrator -H 'content-type: application/json' | jq .
# {
# "entity-type": "bulkStatus",
# "commandId": "e8cc059d-6b9d-480b-a6e1-b0edace6d982",
# "state": "RUNNING",
# "processed": 0,
# "total": 1844,
# "submitted": "2018-10-11T13:10:26.825Z",
# "scrollStart": "2018-10-11T13:10:26.827Z",
# "scrollEnd": "2018-10-11T13:10:26.846Z",
# "completed": null
#}
## Wait for the completion of the command, this is only for testing purpose
## a normal client should poll the status regularly instead of using this call:
curl -X POST 'http://localhost:8080/nuxeo/site/automation/Bulk.WaitForAction' -u Administrator:Administrator -H 'content-type: application/json' -d $'{
"context": {},
"params": {
"commandId": "'"$commandId"'",
"timeoutSecond": "3600"
}
}'
# {"entity-type":"boolean","value":true}
## Get the status again:
curl -s -X GET "http://localhost:8080/nuxeo/api/v1/bulk/$commandId" -u Administrator:Administrator -H 'content-type: application/json' | jq .
#{
# "entity-type": "bulkStatus",
# "commandId": "e8cc059d-6b9d-480b-a6e1-b0edace6d982",
# "state": "COMPLETED",
# "processed": 1844,
# "total": 1844,
# "submitted": "2018-10-11T13:10:26.825Z",
# "scrollStart": "2018-10-11T13:10:26.827Z",
# "scrollEnd": "2018-10-11T13:10:26.846Z",
# "completed": "2018-10-11T13:10:28.243Z"
#}
It's possible to abort a command, this is useful for long-running command launched by error, or to by pass a command that fails systematically which blocks the entire action processor:
## Abort a command
curl -s -X PUT "http://localhost:8080/nuxeo/api/v1/bulk/$commandId/abort" -u Administrator:Administrator -H 'content-type: application/json' | jq .
Debugging
All streams used by the bulk service and action can be introspected using
the Nuxeo bin/stream.sh script.
To get the latest commands submitted:
## When using Kafka
./bin/stream.sh tail -k -l bulk-command --codec avro
| offset | watermark | flag | key | length | data |
|---|---|---|---|---|---|
| bulk-command-01:+2 | 2018-10-11 11:18:34.955:0 | [DEFAULT] | setProperties | 164 | {"id": "b667b677-d40e-471a-8377-eb16dd301b42", "action": "setProperties", "query": "Select * from Document", "username": "Administrator", "repository": "default", "bucketSize": 100, "batchSize": 25, "params": "{\"dc:description\":\"a new new testbulk description\"}"} |
| bulk-command-00:+2 | 2018-10-11 15:10:26.826:0 | [DEFAULT] | csvExport | 151 | {"id": "e8cc059d-6b9d-480b-a6e1-b0edace6d982", "action": "csvExport", "query": "SELECT * FROM File WHERE ecm:isVersion = 0 AND ecm:isTrashed = 0", "username": "Administrator", "repository": "default", "bucketSize": 100, "batchSize": 50, "params": null} |
To get the latest commands completed:
./bin/stream.sh tail -k -l bulk-done --codec avro
| offset | watermark | flag | key | length | data |
|---|---|---|---|---|---|
| bulk-done-00:+4 | 2018-10-11 14:23:29.219:0 | [DEFAULT] | 580df47d-dd90-4d16-b23c-0e39ae363e06 | 96 | {"commandId": "580df47d-dd90-4d16-b23c-0e39ae363e06", "action": "csvExport", "delta": false, "processed": 3873, "state": "COMPLETED", "submitTime": 1539260607207, "scrollStartTime": 1539260607275, "scrollEndTime": 1539260607326, "completedTime": 1539260609218, "total": 3873, "result": null} |
| bulk-done-00:+5 | 2018-10-11 15:10:28.244:0 | [DEFAULT] | e8cc059d-6b9d-480b-a6e1-b0edace6d982 | 96 | {"commandId": "e8cc059d-6b9d-480b-a6e1-b0edace6d982", "action": "csvExport", "delta": false, "processed": 1844, "state": "COMPLETED", "submitTime": 1539263426825, "scrollStartTime": 1539263426827, "scrollEndTime": 1539263426846, "completedTime": 1539263428243, "total": 1844, "result": null} |
To view the BulkBucket message:
./bin/stream.sh tail -k -l bulk-csvExport --codec avro
| offset | watermark | flag | key | length | data |
|---|---|---|---|---|---|
| bulk-csvExport-01:+48 | 2018-10-11 15:10:26.842:0 | [DEFAULT] | e8cc059d-6b9d-480b-a6e1-b0edace6d982:18 | 3750 | {"commandId": "e8cc059d-6b9d-480b-a6e1-b0edace6d982", "ids": ["763135b8-ca49-4eea-9a52-1ceaa227e60a", ...]} |
And check for any lag on any computation, for more information on stream.sh:
./bin/stream.sh help