This page summarizes all the main concepts about documents, access to documents and document storage.
Document in Nuxeo
Document vs File
Inside the Nuxeo repository, a document is not just a simple file.
A document is defined as a set of fields.
Fields can be of several types:
- Simple fields (String, Integer, Boolean Date, Double),
- Simple lists (multi-valued simple field),
- Complex types.
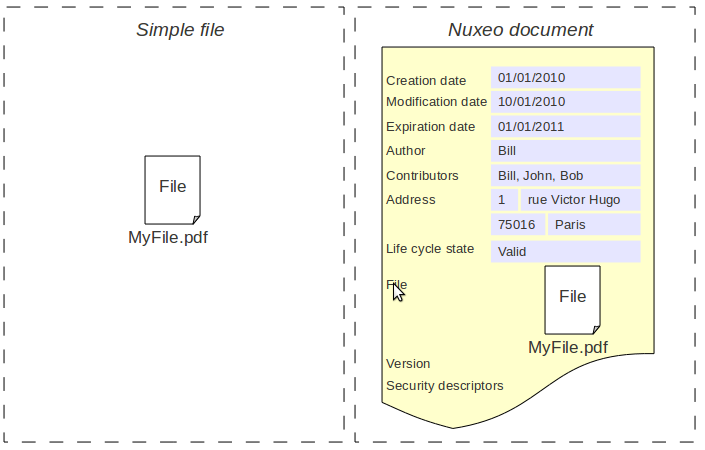
A file is a special case of a complex field that contains:
- A binary stream,
- A filename,
- A mime-type,
- A size.
As a result, a Nuxeo Document can contain zero, one or several files.
In fact, inside the Nuxeo repository, even a folder is seen as a document because it holds metadata (title, creation date, creator, ...).
Schemas
Document structure is defined using XSD schemas.
XSD schemas provide:
- A standard way to express structure,
- A way to define metadata blocks.
Each document type can use one or several schemas.
Here is a simple example of a XSD schema used in Nuxeo Core (a subset of Dublin Core):
<?xml version="1.0"?>
<xs:schema
targetNamespace="http://www.nuxeo.org/ecm/schemas/dublincore/"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:nxs="http://www.nuxeo.org/ecm/schemas/dublincore/">
<xs:simpleType name="subjectList">
<xs:list itemType="xs:string"/>
</xs:simpleType>
<xs:simpleType name="contributorList">
<xs:list itemType="xs:string"/>
</xs:simpleType>
<xs:element name="title" type="xs:string"/>
<xs:element name="description" type="xs:string"/>
<xs:element name="subjects" type="nxs:subjectList"/>
<xs:element name="rights" type="xs:string"/>
<xs:element name="source" type="xs:string"/>
<xs:element name="coverage" type="xs:string"/>
<xs:element name="created" type="xs:date"/>
<xs:element name="modified" type="xs:date"/>
<xs:element name="issued" type="xs:date"/>
<xs:element name="valid" type="xs:date"/>
<xs:element name="expired" type="xs:date"/>
<xs:element name="format" type="xs:string"/>
<xs:element name="language" type="xs:string"/>
<xs:element name="creator" type="xs:string"/>
<xs:element name="contributors" type="nxs:contributorList"/>
</xs:schema>
A schema file has to be referenced by Nuxeo configuration to be found and used. The schema must be referenced in the schema extension point of the org.nuxeo.ecm.core.schema.TypeServicecomponent. A reference to a schema defines:
- the schema name,
- the schema location (file),
- an optional (but recommended) schema prefix.
For example, in the configuration file OSGI-INF/types-contrib.xml (the name is just a convention) you can define:
<?xml version="1.0"?>
<component name="org.nuxeo.project.sample.types">
<extension target="org.nuxeo.ecm.core.schema.TypeService" point="schema">
<schema name="sample" src="schemas/sample.xsd" prefix="smp" />
</extension>
</component>
We name our schema "sample", and the .xsd file is referenced through its path, schemas/sample.xsd. The schema is registered through the schema extension point of the Nuxeo component org.nuxeo.ecm.core.schema.TypeService. Our own extension component is given a name, org.nuxeo.project.sample.types, which is not very important as we only contribute to existing extension points and don't define new ones — but the name must be new and unique.
Finally, like for all components defining configuration, the component has to registered with the system by referencing it from the META-INF/MANIFEST.MF file of the bundle.
In our example, we tell the system that the OSGI-INF/types-contrib.xml file has to be read, by mentioning it in the Nuxeo-Component part of the META-INF/MANIFEST.MF:
Manifest-Version: 1.0
Bundle-SymbolicName: org.nuxeo.project.sample;singleton:=true
Nuxeo-Component: OSGI-INF/types-contrib.xml
...
You may need to override an existing schema defined by Nuxeo. As usual, this possible and you have to contribute a schema descriptor with same name. But you must also add an override parameter with value "true".
For instance, you can add your own parameters into the user.xsd schema to add the extra information stored into your ldap and fetch them and store them into the principal instance (that represents every user).
The contribution will be something like:
<component name="fr.mycompanyname.myproject.schema.contribution">
<!-- to be sure to deployed after the Nuxeo default contributions -->
<require>org.nuxeo.ecm.directory.types</require>
<extension target="org.nuxeo.ecm.core.schema.TypeService" point="schema">
<schema name="group" src="directoryschema/group.xsd" override="true"/>
</extension>
</component>
Focus your attention on the override="true"& that is often missing.
You will need to improve the UI to also display your extra-informations...
Document Types
Inside the Nuxeo Repository, each document has a Document Type.
A document type is defined by:
- A name,
- A set of schemas,
- A set of facets,
- A base document type.
Document types can inherit from each other.
By using schemas and inheritance you can carefully design how you want to reuse the metadata blocks.
At pure storage level, the facets are simple declarative markers. These marker are used by the repository and other Nuxeo Platform services to define how the document must be handled.
Default facets include:
- Versionnable,
- HiddenInNavigation,
- Commentable,
- Folderish,
- ...
Here are some Document Types definition examples:
<doctype name="File" extends="Document">
<schema name="common"/>
<schema name="file"/>
<schema name="dublincore"/>
<schema name="uid"/>
<schema name="files"/>
<facet name="Downloadable"/>
<facet name="Versionable"/>
<facet name="Publishable"/>
<facet name="Indexable"/>
<facet name="Commentable"/>
</doctype>
<doctype name="Folder" extends="Document">
<schema name="common"/>
<schema name="dublincore"/>
<facet name="Folderish"/>
<subtypes>
<type>Folder</type>
<type>File</type>
<type>Note</type>
</subtypes>
</doctype>
At UI level, Document Types defined in the repository are mapped to high level document types that have additional attributes:
- Display name
- Category
- Icon
- Visibility
- ...
<type id="Folder">
<label>Folder</label>
<icon>/icons/folder.gif</icon>
<bigIcon>/icons/folder_100.png</bigIcon>
<icon-expanded>/icons/folder_open.gif</icon-expanded>
<category>Collaborative</category>
<description>Folder.description</description>
<default-view>view_documents</default-view>
<subtypes>
<type>Folder</type>
<type>File</type>
<type>Note</type>
</subtypes>
<layouts mode="any">
<layout>heading</layout>
</layouts>
<layouts mode="edit">
<layout>heading</layout>
<layout>dublincore</layout>
</layouts>
<layouts mode="listing">
<layout>document_listing</layout>
<layout>document_listing_compact_2_columns</layout>
<layout>document_listing_icon_2_columns</layout>
</layouts>
</type>
The label, description, icon, bigIcon and category are used by the user interface, for instance in the creation page when a list of possible types is displayed.
- label: a short name for the type.
- description: a longer description of the type.
- icon: a 16x16 icon path for the type, used in listings for instance. The path points to a resource defined in the Nuxeo WAR.
- bigIcon: a 100x100 icon path for the type, used in the creation screen for instance.
- category: a category for the type, used to separate types in different sections in the creation screen for instance.
Standard categories used in the Nuxeo DM interface are:
- SimpleDocument: a simple document
- Collaborative: a document or folder-like objects used for collaboration
- SuperDocument: a structural document usually created by the system
Other categories can freely be defined.
Lifecycle
Nuxeo Core includes a lifecycle service.
Each document type can be bound to a lifecycle. The lifecycle is responsible for defining:
- The possible states of the document (ex: draft, validated, obsolete, ...),
- The possible transitions between states (ex : validate, make obsolete, ...).
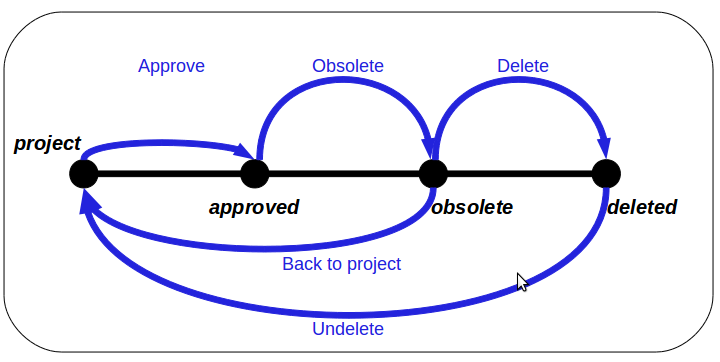
Lifecycle is not workflow, but:
- Workflows usually use the lifecycle of the document as one of the state variable of the process
- You can simulate simple review process using lifecycle and listeners (very easy to do using Nuxeo Studio and Content Automation).
Proxies
The Nuxeo Repository includes the concept of Proxy.
A proxy is very much like a symbolic link on an Unix-like OS: a proxy points to a document and will look like a document from the user point of view:
- The proxy will have the same metadata as the target document,
- The proxy will hold the same files as the target documents (since file is a special kind of metadata).
A proxy can point to a live document or to a version (check in archived version).
Proxies are used to be able to see the same document from several places without having to duplicate any data.
The initial use case for proxies in the Nuxeo Platform is local publishing: when you are happy with a document (and possibly successfully completed a review workflow), you want to create a version for this document. This version will be the one validated and the live document stays in the workspace where you created it. Then you may want to give access to this valid document to several people. For that, you can publish the document into one or several sections: this means creating proxies pointing to the validated version. Depending on their rights, people that cannot read the document from the workspace (because they can not access it) may be able to see it from one or several sections (that may even be public).
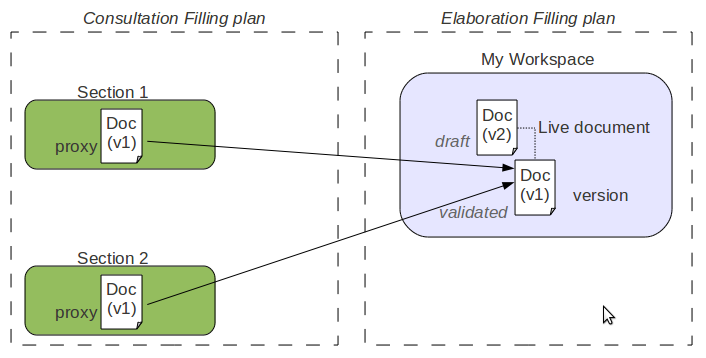
The second use cases for proxies is multi-filling.
If a proxy can not hold metadata, it can hold security descriptors (ACP/ACL). So a user may be able to see one proxy and not an other.
- The
Document.CreateLiveProxyoperation can only be called by administrators. - The
CoreSession#createProxyJava API can only be called if the current user has Write permission on the document targetted by the proxy. This restriction can be relaxed by setting theorg.nuxeo.proxy.creation.restrictedconfiguration property tofalse.
Repository Storage: VCS and DBS
The Nuxeo repository consists of several services.
One of them is responsible for actually managing persistence of documents. This service is pluggable. The Nuxeo Platform repository uses its own persistence backends: VCS and DBS.
VCS (Visible Content Store)
Nuxeo VCS was designed to provide a clean SQL Mapping. This means that VCS does a normal mapping between XSD schemas and the SQL database:
- A schema is mapped as a table,
- A simple field is mapped as a column,
- A complex type is mapped as a foreign key pointing to a table representing the complex type structure.
Using such a mapping provides several advantages:
- A DBA can see the database content and fine tune indexes if needed,
- You can use standard SQL based BI tools to do reporting,
- You can do low level SQL bulk inserts for data migration.
In addition, VCS provides a native cluster mode that does not rely on any external clustering system. This means you can have two (or more) Nuxeo servers sharing the same data: you only have to turn on Nuxeo VCS Cluster mode.
Advantages of VCS:
- SQL Storage is usage by DBAs and by BI reporting tools,
- Supports Hot Backup,
- Supports Cluster mode,
- Supports extra features,
- Supports low level SQL bulk imports,
- VCS scales well with big volumes of Documents.
You can read more about it on the VCS Page.
DBS (Document-Based Storage)
DBS allows storage of Nuxeo documents inside a document-oriented store, like MongoDB or MarkLogic.
You can read more about it on the DBS Page.
Blob Providers
Binary files are never stored in the database, they are stored via the Blob Manager and the configurable Blob Providers on the file system, or in an external blob storage backend, using their digest.
This storage strategy as several advantages:
- Storing several times the same file in Nuxeo won't store it several time on disk,
- Binary storage can be easily snapshotted.
Advanced Features
Lazy Loading and Binary Files Streaming
In Java API, a Nuxeo document is represented as a DocumentModel object.
Because a Document can be big (lots of fields including several files), a DocumentModel object could be big:
- Big object in memory,
- Big object to transfer on the network (in case of remoting),
- Big object to fetch from the storage backend.
Furthermore, even when you have very complex documents, you don't need all these data on each screen: in most screens you just need a few properties (title, version, lifecycle state, author, ...).
In order to avoid these problems, the Nuxeo DocumentModel supports lazy-fetching: a DocumentModel is by default not fully loaded, only the schemas defined as prefetch are initially loaded. The DocumentModel is bound to the repository session that was used to read it and it will transparently fetch the missing data, block per block when needed.
You still have the possibility to disconnect a DocumentModel from the repository (all data will be fetched), but the default behavior is to have a lightweight Java object that will fetch additional data when needed.
The same kind of mechanism applies to files, with one difference: files are transported via a dedicated streaming service that is built-in. Because default RMI remoting is not so smart when it comes to transferring big chuck of binary data, Nuxeo uses a custom streaming for transferring files from and to the repository.
Transaction Management
The Nuxeo repository uses the notion of Session.
All the modifications to documents are done inside a session and modifications are saved (written in the back end) only when the session is saved.
In a JTA/JCA aware environment, the repository session is bound to a JCA Connector that allows:
- The repository session to be part of the global JTA transaction,
- The session to be automatically saved when the transaction commits.
This means that in a JTA/JCA compliant environment you can be sure that the repository will always be safe and have the expected transactional behavior. This is important because a single user action could trigger modifications in several services (update documents in repository, update a workflow process state, create an audit record) and you want to be sure that either all these modifications are done, or none of them: you don't want to end up in an inconsistent state.
DocumentModel Adapter
In a lot of cases, documents are used to represent Business Object: invoice, subscription, contract...
The DocumentModel class will let you design the data structure using schemas, but you may want to add some business logic to it:
- Providing helper methods that compute or update some fields,
- Adding integrity checks based on business rules,
- Adding business methods.
For this, Nuxeo Core contains an adapter system that lets you bind a custom Java class to a DocumentModel. The binding can be made directly against a document type or can be associated to a facet.
By default, The Nuxeo Platform provides some generic adapters:
- BlobHolder: Lets you read and write binary files stored in a document
- CommentableDocument: Encapsulates comment service logic so that you can easily comment a document
- MultiViewPicture: Provides an abstraction and easy API to manipulate a picture with multiple views
- ...